
El sastre que cose a medida… ¿o que tapa los agujeros?
Imagina que eres sastre de una firma de moda prêt-à-porter y te encargan un patrón para un traje. Tu trabajo es que el traje le quede bien a cualquier persona de complexión estándar, no solo a un cliente concreto. Si te dedicas a rellenar cada bulto y disimular cada asimetría con un parche ad hoc, el traje le quedará impecable a ese cliente… pero en cuanto se lo ponga otra persona, parecerá que lleva puesto un saco de patatas con pretensiones.
En Econometría ocurre exactamente lo mismo. Cuando estimamos un modelo de regresión, nuestro objetivo no es simplemente «explicar» los datos que tenemos delante, sino capturar la relación estructural entre las variables, de modo que el modelo funcione también fuera de la muestra. Un modelo que se ajusta demasiado bien a los datos de estimación puede haber aprendido el ruido, no la señal. En este experimento hemos fabricado un caso de laboratorio para ilustrar una práctica muy extendida —y muy tentadora— entre analistas y estudiantes: el uso de variables dummy (ficticias) para «corregir» observaciones anómalas o outliers dentro de la muestra. El resultado es un R² cada vez mayor. La tentación de publicar ese modelo es enorme.
El problema es que, fuera de la muestra, ese R² inflado no vale gran cosa.
El experimento: datos, modelos y outliers.
Hemos generado una serie temporal anual de 25 observaciones (2000-2024). La variable dependiente y responde a dos explicativas, x1 y x2. Para hacerlo más interesante —y realista— hemos introducido tres observaciones anómalas en distintos puntos de la muestra.
Estas tres anomalías no son producto de mala suerte: son perturbaciones que cualquier variable económica real puede sufrir (shocks de política, crisis, eventos extraordinarios). La cuestión es cómo responde el económetra ante ellas.
Hemos estimado cuatro especificaciones del mismo modelo de regresión:
• Modelo 1 (M1): solo x1 y x2. El modelo base, parsimonioso y honesto.
• Modelo 2 (M2): M1 + una dummy que vale 1 en el outlier más evidente (residuo más grande). ¡Alguien encontró la anomalía más gorda!
• Modelo 3 (M3): M2 + una dummy para el segundo outlier. Ya vamos cogiendo ritmo…
• Modelo 4 (M4): M3 + una dummy para el tercer outlier. A este paso, ponemos una dummy por cada año del siglo XX.
La lógica es clara: cada dummy «explica» una anomalía al decirle al modelo que ese año fue especial. Matemáticamente, la dummy absorbe el residuo de ese punto. El resultado inevitable es que R² sube. Siempre. Sin excepción. Es una ley matemática tan infalible como la del IVA: nunca falla cuando toca pagar.
Resultados de la estimación: la ilusión del R² creciente
La Tabla 1 recoge los resultados de los cuatro modelos. Obsérvese cómo evolucionan las métricas de bondad de ajuste al añadir dummies:
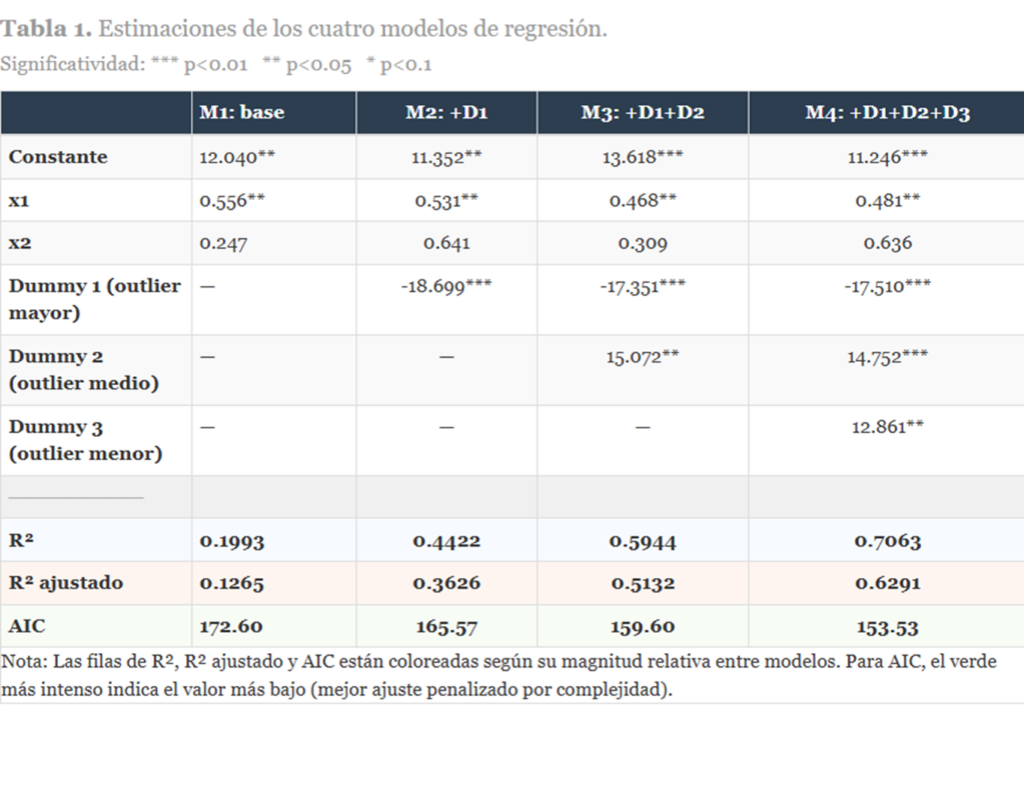
El R² pasa del 19,9% en M1 hasta el 70,6% en M4. Impresionante, ¿verdad? Aquí es donde muchos estudiantes (y no pocos investigadores) cometen el error de proclamar: «¡El Modelo 4 es claramente el mejor!»
Pero antes de correr a publicarlo, conviene hacerse una pregunta incómoda: ¿mejor para qué? Fijémonos en el R² ajustado, que penaliza la incorporación de variables adicionales. También sube, sí, pero más moderadamente (de 0,127 a 0,629). Y el AIC, que penaliza la complejidad, también mejora de forma consistente… lo cual, a priori, parece dar la razón al modelo con más dummies.
Pero aquí viene el truco: todas estas métricas son métricas dentro de la muestra. Miden qué tan bien el modelo «recuerda» los datos que ya ha visto. Son como el examen de tipo test en que tienes el libro delante: claro que te salen bien las respuestas.
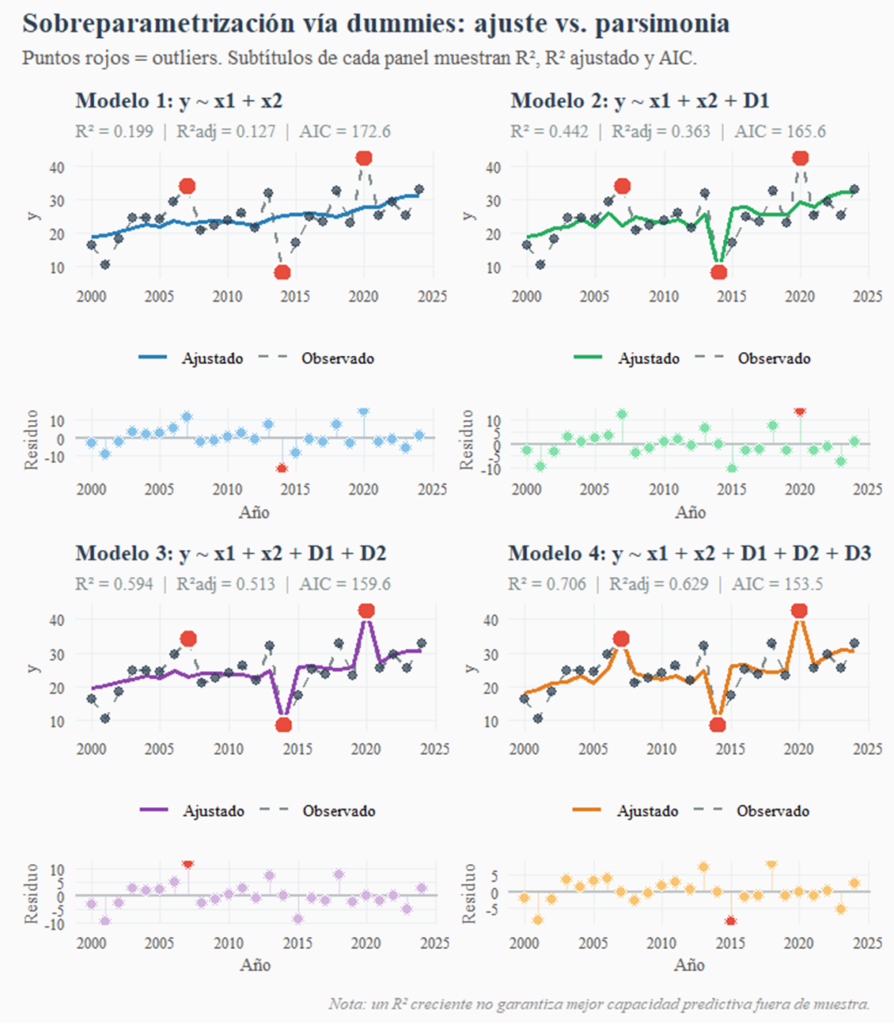
La figura anterior lo deja claro visualmente. A medida que añadimos dummies, la línea de valores ajustados se acerca más a los puntos observados, especialmente en los outliers. En el Modelo 4, los residuos de esas tres observaciones son prácticamente cero. ¿Es eso bueno? Si el objetivo es predecir, no: el modelo ha memorizado un accidente, no ha aprendido una ley.
La prueba de fuego: predecir fuera de la muestra
Para demostrar que un R² alto no garantiza mejor capacidad predictiva, hemos construido tres escenarios de predicción para los años 2025-2029. En todos ellos, las dummies valen 0, porque en el futuro no sabemos de antemano si va a ocurrir algo anómalo ni cuándo.
• Escenario A – Inercia normal: el comportamiento futuro de y sigue una dinámica similar a la de la muestra. Sin grandes sorpresas.
• Escenario B – Mayor varianza: la variable y oscila más de lo habitual, pero sin que ningún valor sea propiamente un outlier. Un entorno algo más turbulento.
• Escenario C – Outlier futuro: similar al A, pero con una observación claramente anómala en el tercer año del horizonte predictivo. La prueba más dura para todos los modelos.
Calculamos el Error Medio Absoluto (MAE) como medida de error predictivo. El MAE tiene la virtud de ser interpretable en las mismas unidades que y, y de no castigar excesivamente los errores grandes (a diferencia del error cuadrático medio).
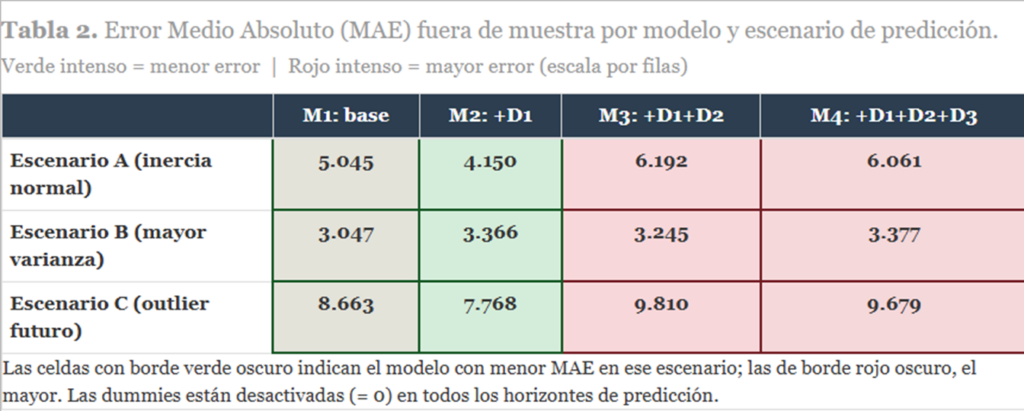
Los resultados de la Tabla 2 son, en cierto modo, el corazón del post. Comentémoslos con calma:
Escenario A (inercia normal)
El ganador es M2 (MAE = 4,15), no el modestísimo M1 ni, desde luego, los recargados M3 y M4. ¿Por qué gana M2? En este experimento concreto, la dummy de M2 recoge el outlier más impactante de la muestra, lo que mejora ligeramente la estimación de los demás coeficientes. Pero el mensaje importante es que M4, el de mayor R², obtiene el peor MAE junto con M3. La sobreparametrización lastra la predicción.
Escenario B (mayor varianza)
Aquí M1 es el más preciso (MAE = 3,05). Con un entorno algo más volátil pero sin anomalías concretas, el modelo más sencillo generaliza mejor. Los modelos con dummies cargan con «recuerdos» que en este escenario no sirven para nada. La parsimonia gana.
Escenario C (outlier futuro)
Ningún modelo predice bien el outlier futuro, porque nadie lo anticipa (las dummies están a 0). Pero los modelos sobreparametrizados (M3 y M4) se llevan los peores MAE (9,81 y 9,68), mientras que M2 y M1 obtienen 7,77 y 8,66 respectivamente. El modelo más cargado de dummies no protege en absoluto ante sorpresas futuras… lo cual tiene todo el sentido: sus dummies estaban diseñadas para sorpresas pasadas y ya conocidas.
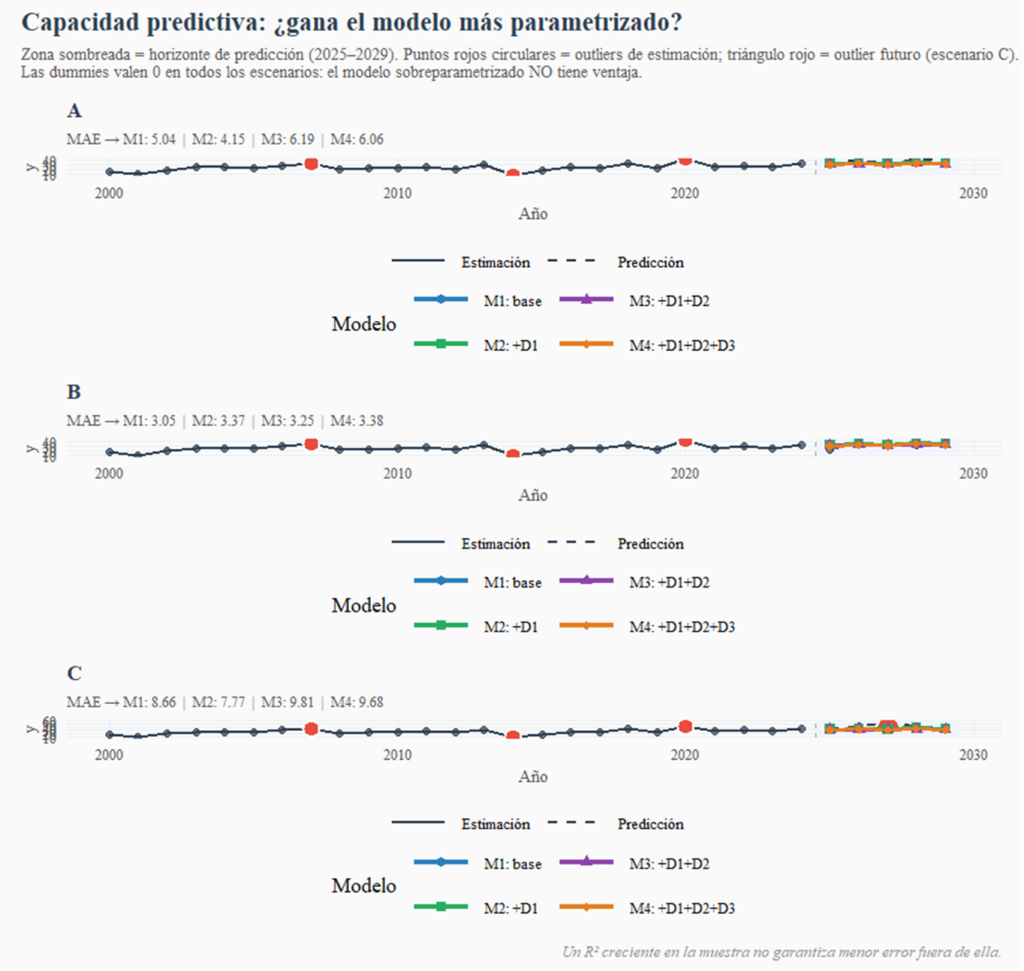
La Figura 2 permite visualizar lo que muestran los números. En todos los escenarios, las cuatro líneas de predicción son prácticamente idénticas en el horizonte futuro: al desactivar las dummies, los cuatro modelos convergen en sus predicciones. Esto revela algo importante: las dummies no estaban aportando información estructural sobre el comportamiento de y, sino simplemente corrigiendo a posteriori puntos inconvenientes.
Lecciones para el estudiante (y para el investigador con memoria corta)
Lección 1: R² es una medida de ajuste en muestra, no de calidad del modelo
El R² siempre puede aumentarse añadiendo variables, aunque sean totalmente irrelevantes. En el límite, un modelo con tantos parámetros como observaciones tiene R² = 1… y predicción = 0. Usar el R² como único criterio de selección de modelos es como juzgar a un cocinero por lo limpio que deja el plato propio.
Lección 2: el R² ajustado y el AIC penalizan la complejidad, pero no son infalibles.
Ambos indicadores mejoran en nuestro experimento al añadir dummies sobre outliers, porque la ganancia en ajuste supera la penalización por el parámetro adicional. Sin embargo, como hemos visto, esa mejora en muestra no se traslada a la predicción. El R² ajustado y el AIC son mejores criterios que el R² simple, pero no sustituyen a la validación fuera de muestra.
Lección 3: una dummy por outlier es una solución cosmética, no estructural.
Cuando una observación es anómala, la pregunta correcta es «¿por qué?», no «¿cómo la elimino del residuo?» Si la anomalía tiene una explicación económica —una crisis, un cambio de régimen, una catástrofe natural— lo adecuado es incorporar esa explicación como variable, no simplemente marcar el año con una dummy y pasar página. La dummy dice: «aquí pasó algo». Pero no dice qué, ni por qué, ni si volverá a pasar.
Lección 4: la parsimonia es una virtud, no una limitación.
El principio de parsimonia —preferir el modelo más sencillo que explique los datos de manera satisfactoria— es uno de los pilares del método científico. En Econometría se materializa en criterios como el AIC o el BIC, y en la práctica de la validación cruzada o la división muestra de estimación / muestra de control. Un modelo parsimonioso generaliza mejor porque no ha «memorizado» los accidentes del pasado.
Lección 5: valida siempre fuera de muestra.
La mejor forma de evaluar un modelo econométrico es comprobar cómo funciona con datos que no ha visto. Esto puede hacerse reservando una parte de la muestra para validación (lo que en machine learning se llama train/test split), o mediante técnicas de validación cruzada. Si solo dispones de una muestra corta, el AIC y el BIC son aproximaciones razonables al error de predicción fuera de muestra… pero siempre con cautela.
Conclusión: el peligro del R² como trofeo
Nuestro experimento de laboratorio demuestra de forma clara y reproducible que la sobreparametrización mediante variables dummy puede inflar espectacularmente el R² sin mejorar —e incluso empeorando— la capacidad predictiva del modelo.
La moraleja no es que las variables dummy sean malas. Son herramientas legítimas y útiles para incorporar efectos estructurales conocidos (cambios legislativos, crisis identificadas, intervenciones de política económica). El problema surge cuando se usan de forma sistemática para maquillar residuos grandes, sin ninguna justificación teórica o empírica más allá de «este punto me molestaba».
La próxima vez que veas un R² de 0,98 en una regresión con series temporales macroeconómicas, no aplaudas demasiado rápido. Pregunta primero: «¿cuántas dummies llevas ahí dentro?» Si la respuesta es más de dos o tres sin justificación económica clara, es momento de ponerse en alerta.
La Estadística no es un concurso de belleza del ajuste. Es una herramienta para entender el mundo y, si todo va bien, para anticiparlo. Y para anticipar el futuro, el pasado —con todas sus anomalías cosidas con dummies— no siempre es el mejor maestro.
Deja una respuesta