
El comienzo: ¿para qué sirve un modelo estadístico?
Imagina que quieres saber si el nivel de educación de una persona influye en su salario. Tienes datos de 200 trabajadores: su salario y sus años de estudios. Calculas una regresión y obtienes un coeficiente: por cada año adicional de estudios, el salario sube en media 1.200 euros al año.
Pero ahí surge una pregunta incómoda: ¿ese resultado es real, o podría haber aparecido por puro azar? Aunque educación y salario no tuvieran ninguna relación verdadera, en una muestra concreta de 200 personas siempre habrá algo de correlación espuria, simplemente por la variabilidad aleatoria de los datos. ¿Cómo distinguimos una relación real de una coincidencia?
Para eso existe el contraste de hipótesis, y dentro de él, el p-valor.
¿Qué es el p-valor? Una garantía muy concreta.
El punto de partida del contraste es asumir provisionalmente que no hay ninguna relación: que el coeficiente verdadero es cero. Eso se llama la hipótesis nula (H₀). Luego, se pregunta: si la hipótesis nula fuera cierta, ¿cuál sería la probabilidad de obtener una estimación del coeficiente al menos tan diferente de cero como la que he obtenido, simplemente por azar?
Esa probabilidad es el p-valor.
Si el p-valor de tu coeficiente de educación es 0,03, significa: «si de verdad la educación no tuviera ningún efecto sobre el salario, la probabilidad de que mis datos mostraran una relación tan fuerte como esta (o más fuerte) por pura casualidad sería solo del 3%».
Como esa probabilidad es pequeña, el investigador concluye: «es muy improbable que este resultado sea fruto del azar, así que probablemente la relación es real» y rechaza la hipótesis nula.
El umbral que convencionalmente se usa para tomar esa decisión es p < 0,05, es decir, menos del 5% de probabilidad de que sea azar. Si el p-valor está por debajo de ese umbral, el resultado se considera estadísticamente significativo.
Lo que ofrece ese umbral del 5%… y lo que esconde.
Cuando un investigador adopta el umbral p < 0,05 antes de ver los datos, tiene una garantía concreta: si la hipótesis nula es verdadera (si no hay ningún efecto real), la probabilidad de que sus datos le lleven erróneamente a concluir que sí hay efecto es del 5%. En estadística esto se llama error de tipo I, o tasa de falsos positivos.
Un 5% parece razonable. Significa que si repitiéramos el experimento 100 veces con datos donde no hay ningún efecto (de la educación sobre el salario), solo en 5 de ellas concluiríamos erróneamente que sí lo hay.
Pero esa garantía viene con una condición que rara vez se menciona: el investigador tiene que haber decidido qué modelo estimar antes de «jugar» con los datos. Si no es así, la garantía se rompe. Y aquí es donde empieza el problema.
La moneda trucada.
Imagina que tienes 20 monedas y quieres demostrar que una de ellas está trucada —sale «cara» con más frecuencia de lo normal—. Las lanzas todas a la vez diez veces cada una y miras los resultados. Por puro azar, es casi seguro que alguna de las 20 monedas habrá salido cara 8 o 9 veces de 10. La coges, la muestras, y dices: «¡esta moneda está trucada, la probabilidad de obtener este resultado con una moneda justa es solo del 3%!». Y matemáticamente tienes razón… para esa moneda, analizada en solitario. Pero has ignorado que probaste 19 monedas más antes de encontrarla.
Con el p-valor ocurre lo mismo: si pruebas 20 especificaciones y reportas solo la que da p < 0,05, no estás presentando un test con garantía del 5%. Estás presentando al ganador de un concurso con 20 participantes, como si hubiera competido solo.
De un modo más formal. Si se hacen k tests independientes, la probabilidad de obtener al menos un falso positivo es:
P(al menos un falso positivo) = 1 − (1 − 0,05)^k
Los números que arroja esta fórmula son reveladores: con solo 10 especificaciones la probabilidad de encontrar al menos un falso positivo supera el 40%; con 55, ronda el 65% en teoría —y más del 54% en la simulación empírica que describiremos más adelante—. En el límite, con 200 modelos probados, la probabilidad teórica de encontrar «algo significativo» es prácticamente del 100%, aunque los datos sean puro ruido.
El pescador que siempre vuelve con algo.
Imaginemos ahora un pescador que sale al mar sin haber explorado antes la zona de pesca. No sabe exactamente dónde están los peces, pero tiene una cosa bien clara: no puede volver al puerto con las manos vacías. Así que lanza la red una y otra vez, en distintos lugares, con distintas mallas, a distintas profundidades. Cuando por fin saca algo —aunque sea una bota vieja—, la limpia y la presenta como el fruto de su pericia marinera.
En Estadística y Econometría existe un pescador igualmente obstinado. Se llama specification search, y su red es el p-valor. Lanza modelos al mar de los datos una y otra vez —cambia variables, transforma, añade, quita, reordena— hasta que algún coeficiente arroja un p-valor por debajo de 0,05. Entonces se detiene, sonríe, y escribe: «el coeficiente es estadísticamente significativo al 5%». El problema es que ese 0,05 ya no significa lo que debería significar.
¿Dónde está el problema?
Una reflexión importante: la inmensa mayoría de los investigadores que practican specification search no son deshonestos. Lo que ocurre es más sutil y más peligroso. El proceso suele ser así (un ejemplo):
- El investigador tiene una hipótesis: el gasto en I+D aumenta la productividad.
- Estima un modelo. El coeficiente sale con p-valor = 0,12. No es significativo.
- Piensa: «quizás debería controlar también por el tamaño de la empresa». Lo añade. Ahora el p-valor = 0,08. Todavía no.
- «Voy a usar el logaritmo de la productividad, que tiene una distribución más simétrica». Ahora p = 0,04. ¡Significativo!
- Escribe el artículo reportando solo ese modelo, justificando que el logaritmo era más apropiado metodológicamente.
Cada decisión tiene una justificación aparentemente razonable. Pero el p-valor de 0,04 ya no tiene la garantía que promete.
Otros factores que alimentan el problema son el sesgo de confirmación —el investigador se detiene cuando encuentra lo que quería—, el HARKing —/Hypothesizing After Results are Known, es decir, presentar una hipótesis formulada a posteriori como si fuera a priori—, y la presión de publicación, dado que las revistas publican resultados significativos con mucha más probabilidad que resultados nulos.
El segundo problema: el coeficiente ganador siempre miente sobre su tamaño.
Hay un segundo efecto del p-hacking que es menos conocido pero igual de grave: la maldición del ganador (winner’s curse).
Entre todas las especificaciones que prueba el investigador, ¿cuáles tienen más probabilidades de arrojar un p-valor bajo? Las que, por azar, han producido un coeficiente grande. Un coeficiente grande tiene un estadístico t grande, y un estadístico t grande tiene un p-valor pequeño. Por lo tanto, el proceso de seleccionar el modelo con menor p-valor es también, inevitablemente, el proceso de seleccionar el modelo con el coeficiente más grande.
Como consecuencia, podemos apuntar que el coeficiente que publica el investigador no solo puede ser un falso positivo; sino que además es una sobreestimación del efecto. Si el efecto real existiera pero fuera pequeño, el coeficiente publicado lo haría parecer grande. Cuando otros investigadores intentan replicar el estudio y obtienen coeficientes mucho más pequeños, no es porque hayan hecho algo mal: es porque el coeficiente original estaba inflado por el proceso de selección.
El experimento: datos sin señal, modelos con ilusión.
Para demostrar todo esto de forma consistente, el experimento de laboratorio que hemos ideado parte de una premisa radical: los datos no contienen ninguna relación real. La variable dependiente y es puro ruido aleatorio. Las diez variables candidatas x₁–x₁₀ también son puro ruido aleatorio, completamente independiente de y y entre sí. No hay ningún efecto que descubrir. Cualquier resultado «significativo» que aparezca será, por definición, un error.
Luego se simulan 5.000 veces dos comportamientos distintos:
El investigador honesto: estima un único modelo prefijado antes de ver los datos (y en función de x₁, sin más). Su tasa de falsos positivos será cercana al 5% nominal: la garantía funciona porque no ha habido búsqueda.
El investigador pescador: prueba sistemáticamente las 10 regresiones simples de y en función de cada una de las x, y las 45 regresiones de y en función de cada combinación de dos variables x (55 modelos en total). Se queda con el que tiene el p-valor más bajo y lo reporta.
Los resultados mostrarán dos cosas: que el investigador pescador encontrará un resultado «significativo» en torno al 54% de las ocasiones buscando entre 55 modelos, aunque los datos sean ruido puro; y que el coeficiente que reporta el pescador es sistemáticamente más grande en valor absoluto que el del investigador honesto.
Resultados: lo que los números revelan.
La inflación de la tasa de error tipo I.
Recordemos la fórmula que vimos antes:
P(al menos un falso positivo) = 1 − (1 − 0,05)^k
La Tabla 1 recoge los valores que resultan de aplicarla para distintos números de modelos probados, junto con la tasa empírica obtenida en la simulación para los dos escenarios del experimento:
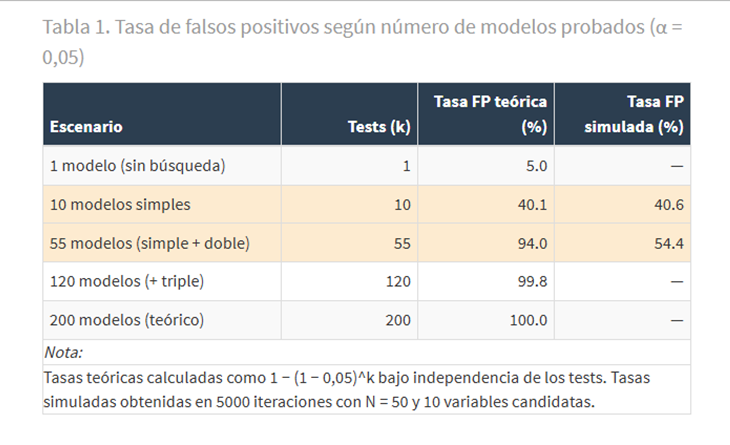
La columna de tasa simulada confirma la predicción teórica: con 55 especificaciones sobre datos de ruido puro, más de la mitad de los experimentos arrojan un resultado «significativo» que en realidad no existe.
La Figura 1A muestra la distribución de los p-valores mínimos obtenidos en las 5.000 simulaciones. Con 10 modelos simples, la tasa de falsos positivos simulada alcanza el 40,6%, ocho veces más que el 5% nominal. Con 55 modelos la tasa sube al 54,4%.
Dicho de otra manera: si un investigador prueba 55 especificaciones con datos completamente aleatorios, encontrará «significatividad estadística» en más de la mitad de los casos. La «estrellita» de «p < 0,05» se convierte en papel mojado.
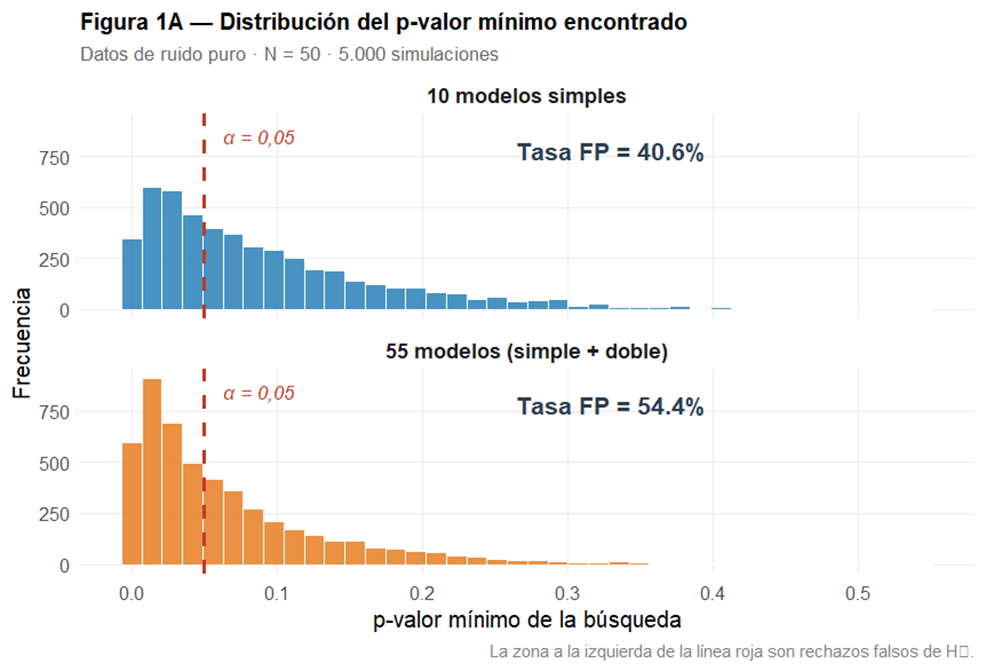
La corrección de Bonferroni: existe el antídoto.
La corrección de Bonferroni divide el umbral α (significación estadística establecida) entre el número de tests realizados. Con 10 modelos el umbral pasa a 0,0050; con 55, a 0,0009. La Tabla 2 muestra el efecto dramático de esta corrección:
Con la corrección aplicada, las tasas de falsos positivos caen al 4,7% y 2,0% respectivamente, recuperando prácticamente la garantía nominal del 5%. El problema es que casi ningún investigador que practica specification search aplica esta corrección, entre otras razones porque hacerlo requeriría admitir cuántas especificaciones se probaron antes de encontrar «la buena».
La maldición del ganador.
La Figura 1B ilustra el sesgo en los coeficientes. El coeficiente honesto tiene una distribución centrada en cero —como debe ser, puesto que no hay efecto real—. El coeficiente pescado tiene colas mucho más pesadas y está claramente separado del cero: los valores seleccionados por su bajo p-valor son también, por construcción, los más extremos.
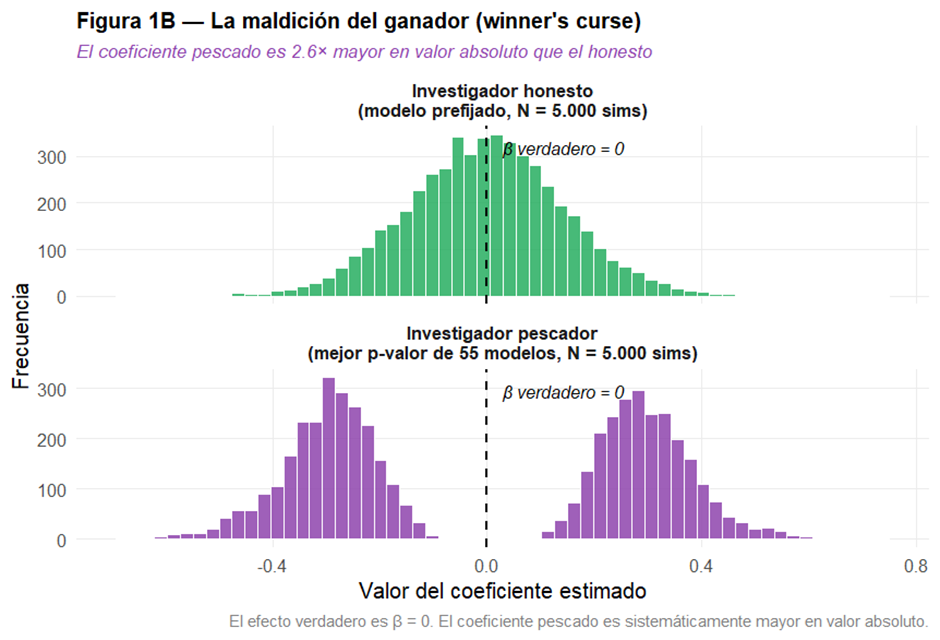
La Tabla 3 cuantifica el sesgo: el coeficiente pescado es 2,6 veces mayor en valor absoluto que el honesto.
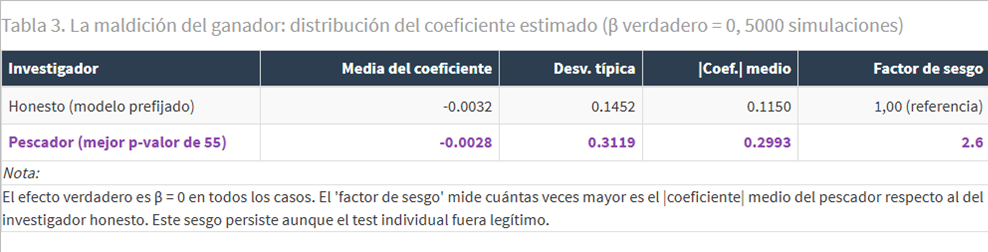
Este sesgo tiene implicaciones directas en la política económica y en la inferencia: cuando publicamos el coeficiente ganador, estamos sobreestimando sistemáticamente el tamaño del efecto. Un meta-análisis que agregue estudios producidos con specification search acumulará ese sesgo, y las revisiones de la literatura llegarán a conclusiones más extremas que la realidad.
Lecciones para el analista (y para quien lee sus resultados).
- El p-valor solo es válido si el modelo fue especificado antes de ver los datos. La inferencia frecuentista asume que el test se define a priori. En cuanto el investigador usa los datos para elegir qué testear, la garantía teórica desaparece.
- La tasa de error real depende del número de tests realizados, no del número reportado. Si probaste 30 especificaciones y reportas solo 1, tu tasa de error tipo I no es 5%: es potencialmente mucho mayor. Reportar todos los modelos probados —o al menos declarar cuántos se probaron— es una práctica de transparencia metodológica básica.
- El coeficiente «significativo» encontrado por búsqueda sistemática es un coeficiente sesgado. La winner’s curse garantiza que los coeficientes seleccionados por su p-valor bajo son, en promedio, más grandes en valor absoluto que el verdadero efecto. La simulación cuantifica ese sesgo en un factor de 2,6×.
- Las correcciones existen y deben usarse. Bonferroni es conservadora pero simple. Benjamini-Hochberg controla la tasa de falsos descubrimientos (FDR) y es más potente cuando hay muchos tests. En Econometría, los criterios AIC/BIC aplicados a un conjunto de modelos predefinidos son preferibles a buscar el modelo de menor p-valor.
Conclusión: la estadística no es una red de arrastre.
El p-valor es una herramienta poderosa cuando se usa como lo que es: la probabilidad de obtener datos tan extremos como los observados si la hipótesis nula fuera cierta, en un experimento diseñado antes de ver los datos. Cuando se convierte en el objetivo de una búsqueda sistemática —cuando el investigador lanza la red una y otra vez hasta que la bota que saca parece un atún—, deja de medir lo que promete medir.
Nuestro experimento de laboratorio lo demuestra sin ambigüedad: con datos de puro ruido, la specification search produce «resultados significativos» en más del 40% de los casos con solo 10 modelos probados, y en más del 54% con 55 modelos. La «estrella» de «p < 0,05» que adorna tantos artículos académicos no es garantía de que algo real haya sido descubierto. A veces es solo el resumen de una tarde de pesca.
Deja una respuesta