
The office.
🤨 La multicolinealidad en el modelo de regresión múltiple, ¿es un problema grave?
Depende.
Imagina una oficina. En ella trabajan varios empleados —los llamaremos regresores— cuya misión conjunta es producir una previsión de la actividad de la empresa (la variable dependiente y). Ahora imagina tres situaciones posibles:
• Escenario 1 — La oficina bien organizada: cada empleado tiene un rol perfectamente definido, no se pisa con nadie, y es bueno en lo suyo. El trabajo sale adelante con eficiencia y eficacia. Esto es lo que los econometristas llamamos un modelo bien especificado, sin multicolinealidad.
• Escenario 2 — La oficina caótica: los empleados son competentes, pero nadie ha definido bien quién hace qué. Se solapan continuamente, repiten tareas, se estorban. Y, sin embargo, el trabajo sale adelante, aunque sea de manera algo desordenada. Este es el escenario de la multicolinealidad: los regresores se duplican mutuamente la información, pero el modelo puede seguir siendo útil para predecir.
• Escenario 3 — La oficina con personal inadecuado: las funciones están bien repartidas y no hay conflictos entre empleados. El problema es que ninguno de ellos es muy bueno en lo suyo. El trabajo no sale adelante. Es el caso de los regresores débiles: variables que, aunque independientes entre sí, simplemente no explican la variable dependiente.
El experimento: tres mundos paralelos con el mismo número de regresores.
Para poner a prueba estas tres situaciones de forma controlada, hemos simulado datos bajo cada escenario y estimado un modelo de regresión lineal con dos variables explicativas. La muestra de estimación tiene 30 observaciones; las 5 restantes se reservan para validación (predecimos esos 5 valores y medimos el error).
Escenario 1: el ideal (x1 y x2 independientes y potentes)
x1 y x2 se generan como variables aleatorias independientes (correlación ≈ 0) y sus coeficientes verdaderos son grandes. El ruido es moderado. El resultado esperado: R² alto, coeficientes significativos, buena predicción. La oficina de ensueño.
Escenario 2: multicolinealidad (x3 y x4 casi colineales)
x4 se construye directamente como una transformación lineal de x3 más un pequeño ruido (x4 ≈ 0.95·x3). La correlación entre ambas ronda 0.96, un nivel de multicolinealidad severa. Sin embargo, el modelo verdadero que genera y utiliza ambas variables con coeficientes sustanciales. ¿Logrará el modelo predecir bien a pesar del caos interno?
Escenario 3: regresores débiles (x5 y x6 irrelevantes)
x5 y x6 son independientes entre sí (correlación ≈ 0), pero sus coeficientes verdaderos son muy pequeños y el ruido es enorme. La señal es casi inexistente. Aquí la oficina está bien organizada, pero los empleados son, lamentémoslo sin rodeos, bastante inútiles para el trabajo que se les encomienda.
Los resultados: cuando los números confirman la metáfora.
La tabla siguiente recoge, de un vistazo, todo lo que necesitamos saber sobre los tres escenarios:
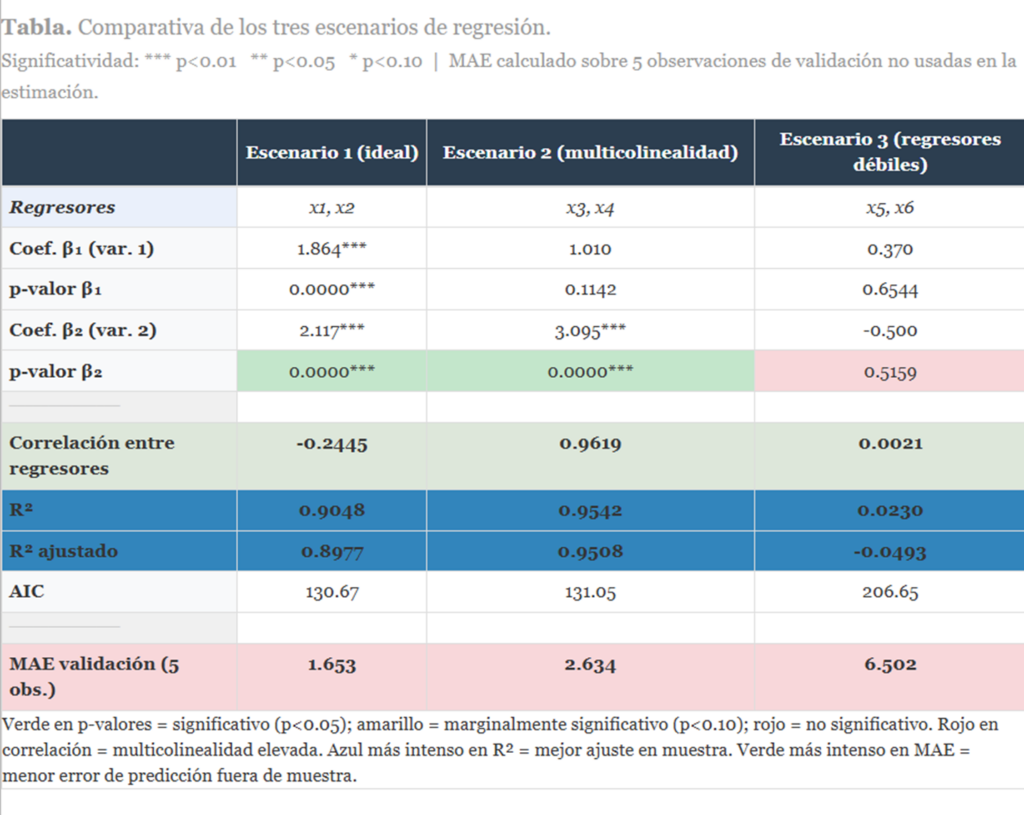
Leamos los resultados con calma, escenario por escenario.
Escenario 1: todo lo que uno esperaría de un modelo bien especificado.
El R² es de 0.905, y el R² ajustado de 0.898. Ambas variables x1 y x2 son altamente significativas (p < 0.001 en los dos casos). La correlación entre regresores es de −0.24, es decir, prácticamente nula. Y el MAE de validación es de 1.65: el modelo predice con una precisión envidiable. Esto es lo que debería ser la norma, aunque en la práctica económica real raramente lo es.
En la oficina del Escenario 1, cada empleado sabe exactamente cuánto ha contribuido al resultado del día y puede demostrar su aportación con un p-valor que lo respalda. Vida sencilla y reconfortante.
Escenario 2: el caos que funciona… a medias
Aquí empieza lo interesante. El R² es incluso mayor que en el Escenario 1: 0.954. El modelo explica casi el 95% de la variabilidad de y. Hasta aquí, buenas noticias.
Pero fijémonos en los coeficientes individuales: el de x3 tiene un p-valor de 0.114, claramente por encima del umbral del 5%. En una lectura apresurada, podríamos concluir que x3 no es relevante. ¡Grave error de interpretación!
Lo que ocurre es que x3 y x4 están tan correlacionadas (r = 0.96) que el modelo no puede repartir el mérito entre ellas. Sabe que algo está explicando la variabilidad de y, pero no consigue distinguir a quién atribuirlo. Es como si dos empleados hicieran exactamente el mismo trabajo: el jefe sabe que la tarea está hecha, pero no sabe a cuál de los dos felicitar. Sin embargo, la capacidad predictiva se mantiene razonablemente buena: el MAE de validación es de 2.63, algo mayor que en el Escenario 1, pero perfectamente aceptable.
La oficina caótica produce, aunque sea desordenadamente. Esto confirma el argumento del post introductorio: la multicolinealidad no es necesariamente un problema grave si el objetivo del modelo es predecir.
El diagnóstico preciso: la multicolinealidad infla los errores estándar de los coeficientes, haciendo que parezcan no significativos individualmente. Pero no deteriora (o lo hace poco) la capacidad explicativa y predictiva del conjunto. Es un problema de identificación, no de ajuste.
Escenario 3: la oficina competente… en el papeleo
El Escenario 3 es el más desolador. La correlación entre x5 y x6 es prácticamente cero (0.002): no hay multicolinealidad. Todo parece en orden. Pero el R² es de 0.023. No es una errata: el modelo explica el 2,3% de la variabilidad de y. Los coeficientes de ambas variables tienen p-valores de 0.65 y 0.52, respectivamente. No son significativos ni de lejos. Y el MAE de validación es de 6.50, cuatro veces mayor que en el Escenario 1.
Aquí no hay multicolinealidad que diagnosticar ni corregir. El problema es más fundamental: las variables x5 y x6 sencillamente no tienen poder explicativo sobre y. Aunque estén perfectamente diferenciadas en sus roles, si ninguna de las dos tiene información útil, el modelo fracasa tanto en la estimación como en la predicción. Es la omisión de variables relevantes por otra vía: en lugar de haber excluido variables importantes, hemos incluido variables irrelevantes.
Lecciones para estudiantes (y para econometristas con el café frío).
Lección 1: no confundir la falta de significación individual con la irrelevancia.
La lección más importante del Escenario 2 es que un coeficiente no significativo no implica automáticamente que la variable sea irrelevante. Si hay multicolinealidad, la falta de significación puede ser un síntoma del solapamiento, no de la ausencia de efecto real. Antes de eliminar una variable por su p-valor, comprueba si está altamente correlacionada con otra del modelo.
Lección 2: el test F y el R² miran al equipo, no al jugador.
El contraste de significación conjunta (test F del modelo) y el R² evalúan si el conjunto de regresores explica y. Si este contraste es significativo con un R² alto, el modelo es útil globalmente, aunque algún coeficiente individual no lo sea. En el Escenario 2, el test F sería altamente significativo. En el Escenario 3, no.
Lección 3: el VIF como termómetro de la multicolinealidad.
Una herramienta estándar para diagnosticar multicolinealidad es el Factor de Inflación de la Varianza (VIF). Un VIF > 5 empieza a ser preocupante; por encima de 10 es severo. En el Escenario 2, el VIF de x3 y x4 sería muy elevado (probablemente > 50), confirmando lo que ya vemos en la correlación. En los Escenarios 1 y 3, el VIF sería cercano a 1, pues las variables son casi ortogonales.
Lección 4: el impacto de la multicolinealidad depende del objetivo.
Esta es quizá la lección más práctica de todas, y la que resume la metáfora de la oficina:
Si el objetivo es predecir: la multicolinealidad es molesta pero generalmente tolerable. Los coeficientes individuales son inestables (cambian mucho de una muestra a otra), pero la predicción conjunta puede ser buena. La oficina caótica entrega el pedido.
Si el objetivo es el análisis estructural (entender qué variable causa qué): la multicolinealidad es un problema serio. No podemos identificar el efecto marginal de cada regresor porque el modelo no puede separar sus contribuciones. La oficina caótica no puede responder quién hizo el trabajo.
Lección 5: lo peor no siempre es lo que más llama la atención.
Los estudiantes suelen temer la multicolinealidad como si fuera la plaga econométrica definitiva. Pero, como hemos visto, el Escenario 3 —sin multicolinealidad alguna— produce resultados mucho peores tanto en estimación como en predicción. La omisión de variables relevantes, o la inclusión de variables irrelevantes, es generalmente más dañina que la correlación entre regresores. La multicolinealidad es, en muchos casos, un problema de precisión; la mala especificación es un problema de validez.
Conclusión: el caos que predice y la calma que no sirve.
La multicolinealidad no es el villano que muchos textos pintan. Es, más bien, un complicador que exige precisión en el diagnóstico y claridad sobre el objetivo del análisis.
Un modelo con multicolinealidad puede ser perfectamente válido para predecir; fallará si se intenta usar para cuantificar efectos causales individuales.
En cambio, un modelo con variables irrelevantes —aunque estén perfectamente desacopladas entre sí— es inútil tanto para predecir como para entender. La correlación entre regresores es un problema de cómo repartimos el mérito; la falta de relevancia es un problema de si hay mérito que repartir.
La próxima vez que un R² bajo te deje helado, no busques la multicolinealidad: busca mejores variables. Y la próxima vez que encuentres coeficientes no significativos con un R² alto, antes de eliminar variables, calcula el VIF. Puede que tus regresores se estén pisando los pies… pero estén sacando el trabajo adelante.
Deja una respuesta