
Bendita Normal.
Hay pocas cosas en las que los científicos sociales estén tan unánimemente de acuerdo como en el amor que profesan a la distribución normal. Y no es para menos: la campana de Gauss es, sin exageración, uno de los inventos intelectuales más rentables de la historia de la Estadística. Simétrica, elegante, completamente descrita por solo dos parámetros —la media y la desviación típica—, y dotada de propiedades matemáticas que hacen que trabajar con ella sea casi un placer. En un mundo donde los modelos estadísticos pueden volverse intratables con rapidez, la Normal es ese colega fiable que siempre llega a tiempo, nunca da problemas y sabe comportarse en cualquier situación.
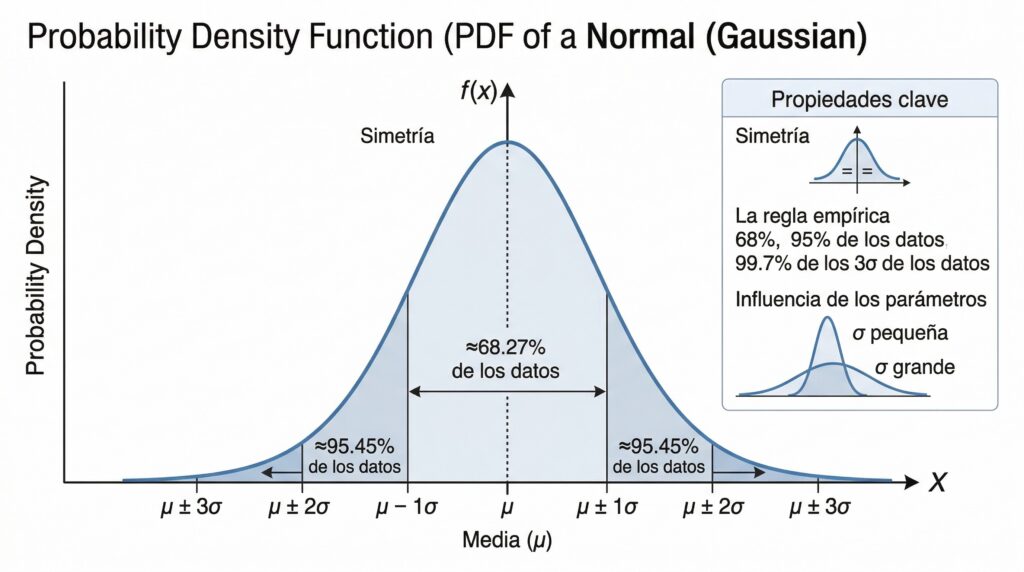
Pero la razón más profunda de su popularidad no es estética sino teórica, y se llama Teorema Central del Límite. En su versión más conocida, este teorema establece que la suma (o la media) de un número suficientemente grande de variables aleatorias independientes, sea cual sea su distribución original, tiende a seguir una distribución normal. Dicho de otro modo: si observas el resultado agregado de muchos fenómenos individuales —el ingreso medio de un barrio, la puntuación media en un test, el gasto medio por cliente—, la Normal aparece casi inevitablemente, como por arte de magia estadística. No importa demasiado si los componentes individuales son asimétricos, discretos o de forma irregular: en el agregado, Gauss siempre acaba ganando. Esto ha dado a generaciones de investigadores una licencia casi universal para asumir normalidad con la conciencia tranquila.
Y así, durante décadas, la Normal se ha colado en modelos de regresión, contrates de hipótesis, intervalos de confianza, modelos de riesgo financiero y hojas de cálculo de todo el mundo. Con frecuencia, con plena justificación.
Con demasiada frecuencia, por pura inercia.
Porque aquí empieza el problema. El Teorema Central del Límite es poderoso, pero no es omnipotente. Requiere que las variables individuales tengan varianza finita —un requisito que suena técnico y aburrido hasta que te das cuenta de que hay fenómenos reales donde esa condición no se cumple. Y cuando no se cumple, la Normal no solo es una aproximación imprecisa: es una ficción peligrosa. Sus colas —esas zonas del gráfico donde viven los eventos extremos— caen exponencialmente rápido, asignando probabilidades ínfimas a sucesos que en la realidad ocurren con una frecuencia perfectamente apreciable. El analista que confía en la Normal para calibrar su exposición al riesgo extremo está, en cierto sentido, usando un «mapa de ciudad» para orientarse en una cordillera: funciona bien en el centro, pero en los bordes del mundo el mapa simplemente deja de existir.
Las consecuencias prácticas de este error no son solo académicas. En finanzas, los modelos basados en normalidad subestimaron sistemáticamente la probabilidad de los crashes que luego ocurrieron, con resultados que el mundo pudo comprobar en 2008. En gestión de riesgos operacionales, las pérdidas catastróficas —ciberataques, fraudes masivos, fallos de infraestructura— aparecen con una frecuencia que ningún modelo normal hubiera predicho. Y en el campo que nos ocupa —como ejemplificación— en este post, el de los seguros, el mismo error tiene nombre propio y consecuencias directas sobre la solvencia de las compañías.
¿Por qué los seguros son un territorio especialmente hostil para la Normal? Porque la distribución de los siniestros individuales es profundamente asimétrica. La gran mayoría son pequeños y predecibles: una gotera, un cristal roto, una cerradura forzada. Pero de vez en cuando —con una frecuencia baja pero no despreciable— aparece un siniestro de una magnitud completamente distinta: una inundación que afecta a cientos de viviendas, un incendio que arrasa un edificio completo, una catástrofe natural que activa miles de pólizas a la vez. Esta estructura —muchos eventos pequeños y algunos eventos gigantescos— es precisamente la firma de las distribuciones de cola pesada, y en particular de la familia Pareto, cuya característica definitoria es que la probabilidad de los eventos extremos decrece mucho más lentamente que en la Normal: no como una campana que se aplana, sino como una rampa que nunca llega a cero.
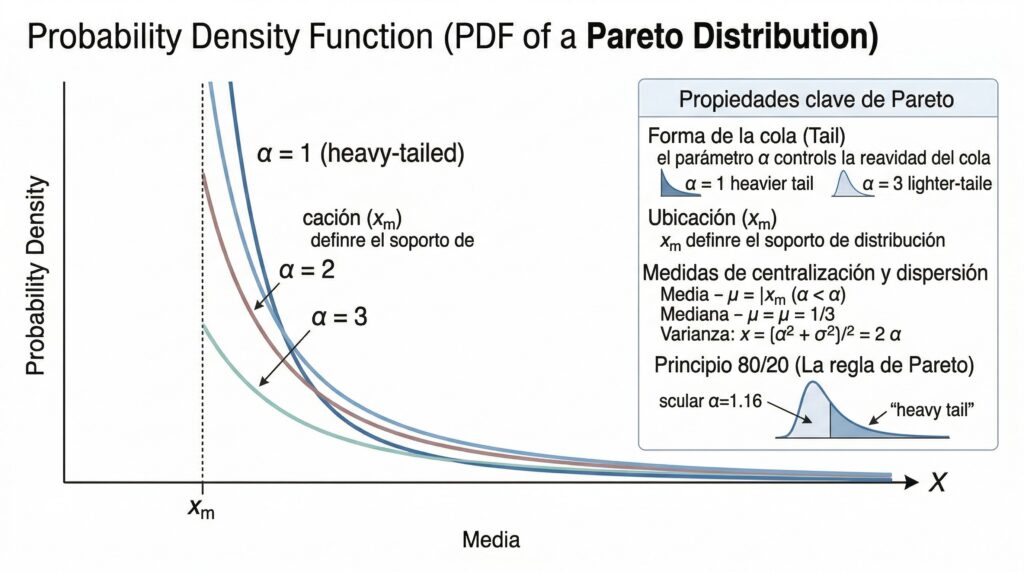
Cuando una aseguradora usa la Normal para estimar el riesgo de su cartera, el modelo le dice que los siniestros catastróficos son tan improbables que no merece la pena reservar capital para ellos. La Pareto le dice algo muy diferente: que esos siniestros son raros, sí, pero no tan raros como para ignorarlos. La diferencia entre esos dos mensajes puede ser, como veremos a continuación, la diferencia entre una empresa sólida y una empresa que quiebra el año en que llega la tormenta que el modelo nunca supo ver.
La aseguradora de Próspero Villaverde.
Permíteme presentarte a Próspero Villaverde, propietario de Seguros Villaverde S.L., una aseguradora familiar que lleva veinte años cubriendo hogares en la provincia. Goteras, calderas que explotan, pequeños incendios de cocina, algún robo ocasional. Un negocio tranquilo, predecible, rentable.
Próspero Villaverde es un hombre metódico. Cada año, antes de fijar las primas del siguiente, abre su hoja de cálculo, mira los siniestros del año anterior, calcula la media y la desviación típica, y fija el precio de sus pólizas con un margen de seguridad. «La estadística no falla», le gusta decir en las cenas de empresa.
Su actuaria, Prudencia Riesgo, lleva años mirándole con una mezcla de respeto y aprensión. Esta es la historia de por qué Prudencia Riesgo tenía razón.
Antes de empezar: unas breves notas sobre seguros.
Para entender el problema de Próspero Villaverde, necesitamos comprender cómo funciona una aseguradora en lo más básico.
Una aseguradora cobra una prima a cada cliente al inicio del año. A cambio, si ese cliente sufre un siniestro —una gotera, un incendio, un robo— la aseguradora paga la reparación. El negocio funciona si, al final del año, lo que la aseguradora ha cobrado en primas supera lo que ha pagado en siniestros.
¿Cómo fija Próspero Villaverde la prima? Con una lógica aparentemente impecable:
«Si el siniestro medio cuesta 1.500 €, y tengo 1.000 clientes, necesito recaudar al menos 1.500.000 € al año solo para cubrir los costes medios. Pero los años malos pueden ser peores que la media, así que añado un margen de seguridad: cobro la media más dos veces la desviación típica. Con eso debería cubrirme en casi cualquier escenario.»
Este razonamiento es correcto… si los siniestros siguen una distribución normal. El problema es que no la siguen. Y Prudencia Riesgo lo sabe.
¿Por qué la distribución de Pareto?
Previo a entrar en el análisis, conviene responder una pregunta que cualquier lector curioso se haría: ¿por qué la distribución de Pareto y no otra?
La respuesta es empírica. Décadas de datos de seguros, catástrofes naturales y pérdidas operacionales muestran que la frecuencia de siniestros grandes no decrece de forma exponencial —como predice la Normal— sino como una ley de potencias: f(x) ∼ x⁻(α+1). Esto significa que los eventos muy grandes son mucho más probables de lo que la Normal predice.
Hay además una razón teórica de peso: el Teorema de Pickands–Balkema–de Haan garantiza que, bajo condiciones muy generales, la distribución de los siniestros que superan un umbral alto converge a una distribución de Pareto Generalizada. Por eso su uso en actuaría no es un capricho, sino una prescripción de la teoría de valores extremos.
En nuestra simulación usamos una Pareto con parámetro de cola α = 1,05. Este valor tiene una propiedad matemática crucial: con α > 1 la media existe (el negocio tiene sentido económico), pero con α < 2 la varianza es infinita. No es una exageración retórica: matemáticamente, la varianza de esta distribución no existe como número finito. Y eso, como veremos, lo cambia todo.
El primer aviso: la desviación típica que no se está quieta.
Antes de entrar en los gráficos de distribuciones, Prudencia Riesgo le muestra a Próspero algo que él nunca se había molestado en comprobar, la figura 0:
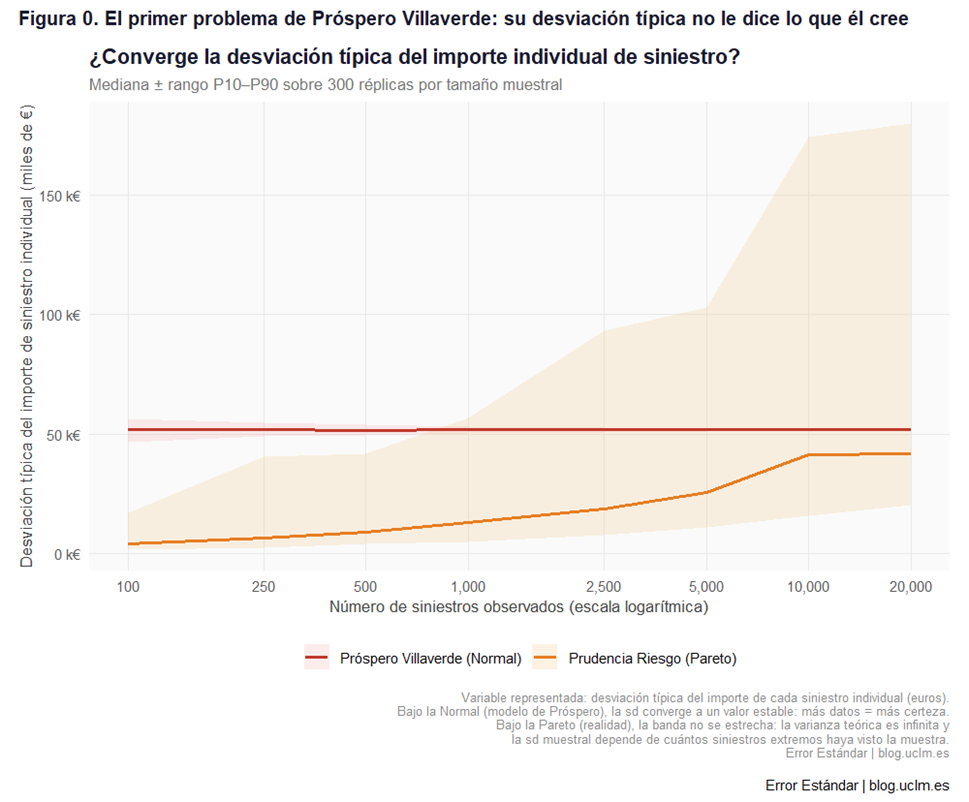
Este gráfico puede parecer técnico a primera vista, pero el mensaje es muy simple. Imagina que puedes repetir el negocio de Próspero muchas veces en universos paralelos, con diferentes clientes pero con la misma realidad subyacente. En cada universo, Próspero calcula su desviación típica a partir de sus datos. ¿Obtendría siempre el mismo número?
La línea roja corresponde al mundo donde Próspero tiene razón: un mundo donde los siniestros siguen una distribución normal. La línea es casi perfectamente plana y la banda a su alrededor es estrecha. Eso significa que en ese mundo, la desviación típica que calcula Próspero es una estimación fiable: da más o menos lo mismo en qué año la calcule, con qué clientes, en qué universo paralelo.
La línea naranja es la realidad: los siniestros siguen una distribución de Pareto. La banda naranja no se estrecha aunque el tamaño muestral crezca. Con 100 clientes, la desviación típica puede estar entre 5.000 y 30.000 €. Con 20.000 clientes, puede estar entre 40.000 y 175.000 €. Más datos no dan más certeza.
¿Por qué? Porque en el mundo Pareto la varianza teórica es infinita. Cada vez que calculas la desviación típica de una muestra nueva, puede aparecer un siniestro descomunal que te la dispara. Lo que Próspero llama «mi desviación típica» no es una estimación del riesgo real. Es el resultado de cuántos años de mala suerte le ha tocado ver hasta ahora.
Cuando Prudencia Riesgo intenta explicarle esto, Próspero responde: «Llevo veinte años calculando esta cifra y nunca me ha fallado.» A lo que Prudencia replica: «Exactamente. Eso es lo que me preocupa.»
El corazón del problema: dos mundos que se parecen en el centro y difieren en todo lo demás.
Observa ahora la figura 1.
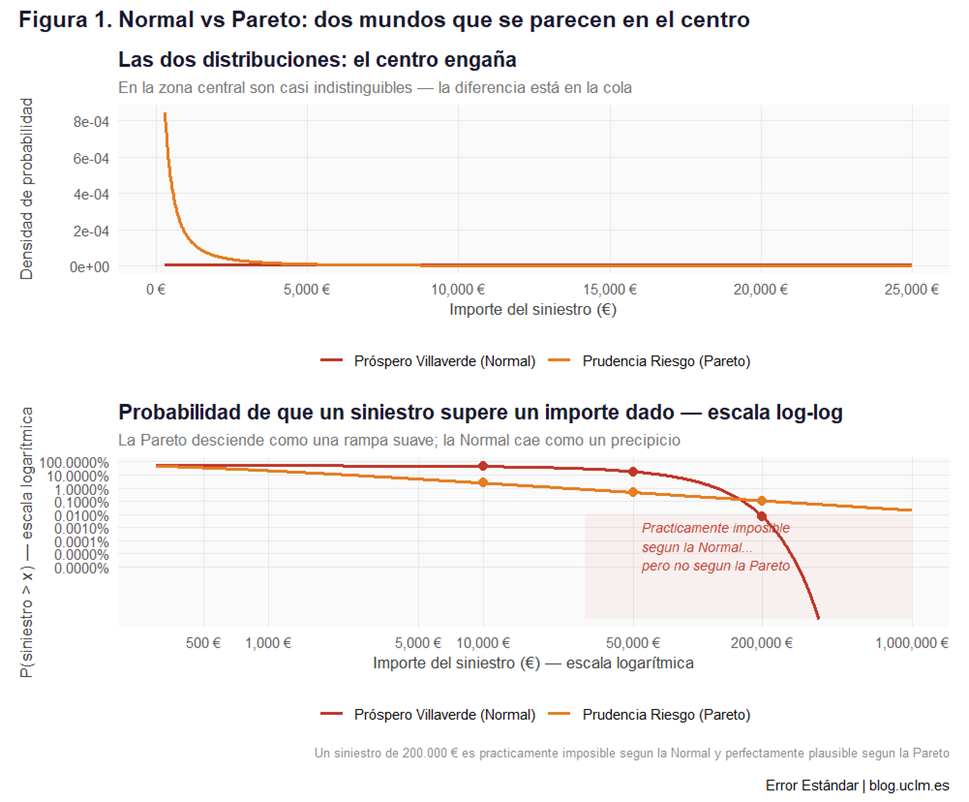
Esta figura tiene dos partes, y juntas cuentan la historia más importante del post.
El centro engaña.
El panel superior muestra la densidad de probabilidad de las dos distribuciones, calibradas para tener aproximadamente la misma media. Observa que en la zona central —entre 0 y 25.000 €, donde caen la inmensa mayoría de los siniestros cotidianos— las dos distribuciones son visualmente muy parecidas. Esto explica por qué Próspero lleva veinte años sin sospechar nada: año tras año, sus siniestros ordinarios encajan perfectamente con su modelo normal.
La cola lo cambia todo.
El panel inferior muestra las mismas distribuciones con una pregunta diferente: ¿cuál es la probabilidad de que un siniestro supere un determinado importe? Este tipo de representación se llama función de supervivencia, y ambos ejes están en escala logarítmica, lo que nos permite ver con claridad lo que ocurre en los siniestros grandes.
La curva roja —la Normal de Próspero— cae en picado como un precipicio. En la zona sombreada en rosa, la Normal asigna una probabilidad tan pequeña que es prácticamente cero: para ella, un siniestro de 200.000 € es un evento «astrónomicamente improbable».
La curva naranja —la Pareto real— desciende suavemente como una rampa. En esa misma zona, la Pareto sigue asignando probabilidades apreciables a siniestros grandes. Un siniestro de 200.000 € no es frecuente, pero tampoco es impensable. Ocurrirá.
El mensaje de este gráfico es el más importante del post: Próspero y Prudencia ven los mismos datos cotidianos y llegan a conclusiones idénticas sobre los siniestros ordinarios. La diferencia no está en el centro, está en la cola. Y la cola es donde se arruinan las aseguradoras.
La simulación: veinte años tranquilos y lo que viene después.
Convertimos ahora el análisis en números concretos.
Previamente, conviene entender cómo fija cada uno el precio de sus pólizas. Próspero Villaverde aplica la lógica que lleva usando veinte años: calcula la media y la desviación típica de los siniestros históricos y cobra una prima igual a la media más dos veces la desviación típica. Bajo una distribución normal, ese margen cubriría el 97,7% de los escenarios posibles —una protección más que razonable. El problema, como ya sabemos, es que los siniestros no son normales.
Prudencia Riesgo, en cambio, no parte de la distribución de cada siniestro individual sino de la distribución de las pérdidas totales anuales: simula miles de años de actividad con la distribución Pareto real, calcula el percentil 99,5 de esas pérdidas agregadas —es decir, el umbral que solo se superaría en el peor 0,5% de los años— y divide entre el número de pólizas, añadiendo un margen de seguridad adicional del 5%. Es un criterio riguroso, basado en cuantiles extremos de la distribución real, no en los parámetros de una distribución asumida por comodidad. El resultado es una prima notablemente más alta que la de Próspero —lo que algunos clientes encontrarán caro y otros encontrarán sensato, dependiendo de si alguna vez han visto llover de verdad.
Simulamos ahora la actividad de Seguros Villaverde bajo tres escenarios:
- Próspero Villaverde (los siniestros siguen una Pareto real, pero él fija las primas asumiendo normalidad);
- Prudencia Riesgo (los siniestros siguen la misma Pareto, pero ella fija las primas conociendo la distribución real);
- y si los siniestros fueran realmente normales (el universo alternativo donde Próspero tiene razón).
La simulación modela trayectorias de 50 años con colchón acumulado: cada aseguradora arranca con un capital inicial equivalente a dos años de sus propios ingresos, acumula capital año a año cuando tiene beneficios, y quiebra cuando el capital acumulado cae por debajo de cero.
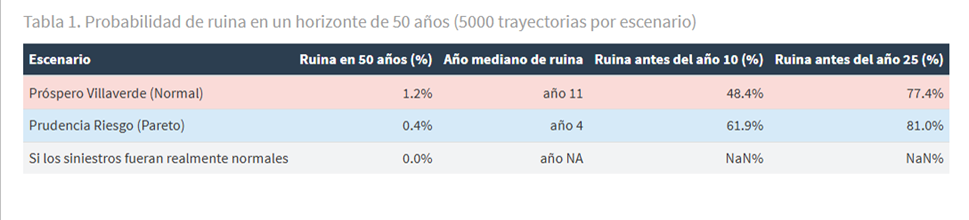
La tabla muestra cuatro métricas por escenario. La tasa de ruina en 50 años mide qué porcentaje de las 5.000 trayectorias acaban en quiebra en algún momento. Próspero Villaverde quiebra más que Prudencia Riesgo: un 1,2% de las trayectorias frente a un 0,4%. Próspero, al cobrar primas insuficientes, erosiona sus reservas lentamente incluso en años normales y llega al eventual año catastrófico con escaso colchón. Prudencia, al cobrar primas correctas, acumula capital año a año y resiste mejor. El escenario Normal puro no quiebra en ninguna de las 5.000 trayectorias, puesto que en este universo los grandes siniestros están totalmente descartados (probabilidad 0).
Ahora, echemos un vistazo a la figura 2.
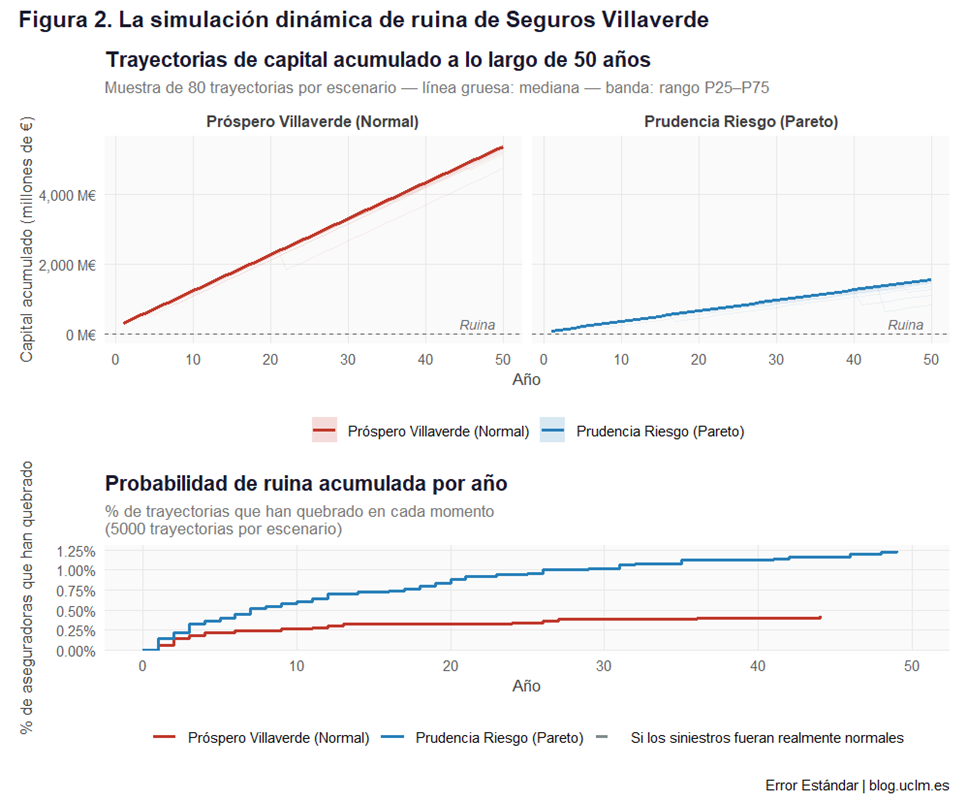
El panel superior muestra las trayectorias de capital acumulado de ambas aseguradoras a lo largo de 50 años. Las trayectorias de Próspero Villaverde crecen más rápido en los años normales —sus primas, aunque incorrectamente calibradas, generan beneficios contables al no cubrir el riesgo real— pero ese colchón es frágil: en cualquier momento puede llegar el año catastrófico que lo borre todo. Las trayectorias de Prudencia Riesgo crecen más lentamente pero de forma más sólida.
El panel inferior muestra la probabilidad de ruina acumulada: la curva de Próspero sube más despacio al principio pero acaba siendo más alta que la de Prudencia. Prudencia tiene alguna quiebra temprana —cuando el año catastrófico llega antes de haber acumulado colchón suficiente— pero a largo plazo su posición es más sólida. La curva del escenario Normal puro permanece en cero durante todo el horizonte.
¿Y si simplemente esperamos tener más datos?
Una respuesta natural al problema de Próspero Villaverde sería: «bueno, con el tiempo tendré más años de historia y mis estimaciones serán más precisas.» Es una intuición razonable. Es también completamente errónea bajo una distribución de Pareto.
Observemos la figura 3.
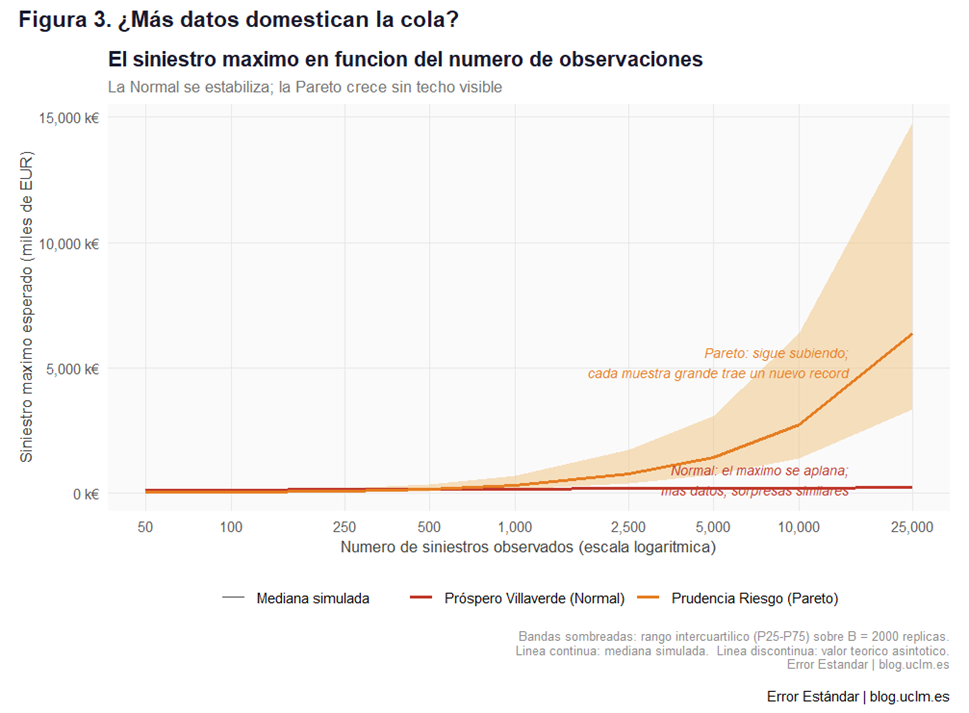
Este gráfico muestra cómo crece el siniestro máximo esperado a medida que aumenta el número de observaciones, tanto bajo la Normal como bajo la Pareto.
La línea roja —Normal— se aplana rápidamente: más datos no traen grandes sorpresas. La línea naranja —Pareto— no se aplana. Bajo la Pareto, el máximo esperado crece aproximadamente como n elevado a 1/α ≈1/1,05, es decir, casi linealmente: si duplicas los datos, el siniestro máximo casi se duplica también.
El mensaje para Próspero es duro pero claro:
«Veinte años de historia no le dicen cuál es el peor siniestro posible. Cuarenta años tampoco. Cada nueva temporada puede traer un récord que haga que todos los anteriores parezcan insignificantes.»
El número que lo dice todo.
Vamos a pararnos ahora en un resultado del experimento clave: la tabla 2. Para cada importe umbral, muestra la probabilidad de que un siniestro individual supere ese importe según la Normal de Próspero y según la Pareto real.
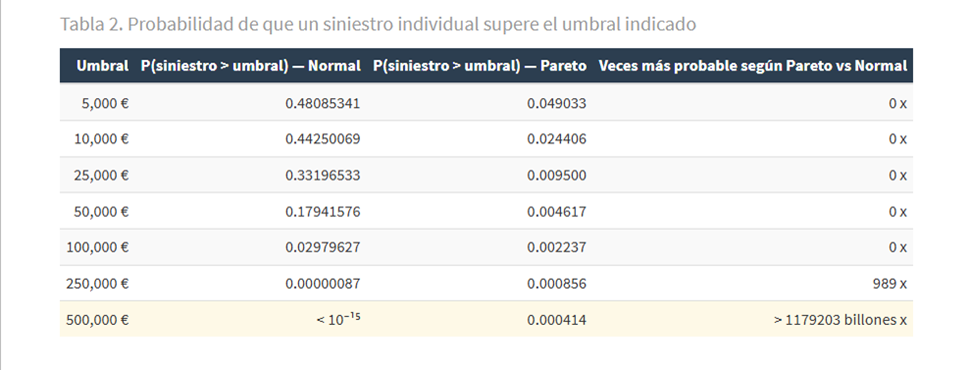
Para un siniestro de 250.000 €, la Normal asigna una probabilidad de 0,00000087 —menos de una en un millón. La Pareto le asigna 0,000856: la ratio es de 989 veces. Para un siniestro de 500.000 €, la Normal asigna menos de 10⁻¹⁵. La Pareto le asigna 0,000414: el ratio supera los mil millones.
Traducido a la vida real: si Próspero tiene 1.000 pólizas, la probabilidad de que en un año dado algún cliente presente un siniestro de más de 500.000 € es, según su modelo, virtualmente cero. Según la distribución real, es aproximadamente un 34%: en uno de cada tres años, algún cliente presentará una reclamación de medio millón de euros o más.
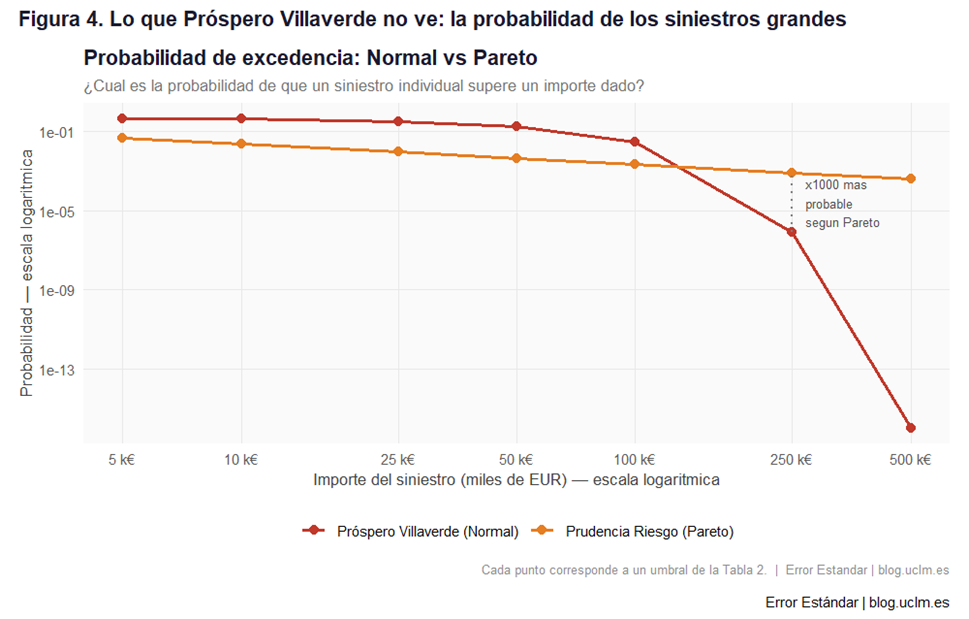
La Figura 4 traduce esos números a una imagen: la curva roja —Normal— cae verticalmente a partir de cierto umbral y desaparece del gráfico, mientras que la curva naranja —Pareto— sigue descendiendo suavemente, siempre visible, siempre presente.
Lecciones para el analista (y para quien gestiona riesgos).
- La elección de la distribución no es un detalle técnico: es una decisión de riesgo. Asumir normalidad porque es cómoda y familiar no es neutral. En contextos donde los siniestros, las pérdidas o los retornos tienen colas pesadas, esa elección tiene consecuencias directas sobre las reservas, las primas y la solvencia. La distribución que impones al modelo define el mundo que el modelo es capaz de ver.
- El Teorema Central del Límite no te salva si la varianza es infinita. El argumento habitual —«con suficientes datos todo se vuelve normal»— tiene un supuesto silencioso: que la varianza de los datos individuales es finita. Cuando ese supuesto no se cumple, el TCL no aplica con la velocidad habitual, y más datos no garantizan más certeza. La desviación típica muestral sigue siendo volátil con decenas de miles de observaciones.
- La ausencia de catástrofes pasadas no es evidencia de que las catástrofes sean improbables. Bajo una distribución de cola pesada, los eventos extremos son raros por definición —pero no tanto como la Normal sugiere. Veinte años sin ver un siniestro de medio millón de euros no significa que ese siniestro tenga una probabilidad de una en un billón. Puede significar simplemente que todavía no ha llegado. El modelo debe construirse para el mundo que puede ocurrir, no solo para el que ha ocurrido hasta ahora.
- El colchón de capital importa tanto como la prima. La simulación dinámica muestra que incluso una distribución correctamente especificada no elimina el riesgo de ruina ante eventos suficientemente extremos. Lo que sí hace la prima correcta es permitir acumular reservas durante los años tranquilos, de modo que cuando llegue el año catastrófico la aseguradora tenga algo con qué absorberlo. Prudencia Riesgo no elimina el riesgo; lo gestiona. Próspero Villaverde ni siquiera sabe que existe.
- La teoría de valores extremos existe y está madura. La distribución de Pareto, la GEV (Generalized Extreme Value distribution) y la GPD (Generalized Pareto Distribution) no son exotismos académicos: son las herramientas estándar de la actuaría moderna y de la gestión de riesgos financieros. Están implementadas en R (paquetes actuar, evd, POT), son razonablemente fáciles de ajustar, y sus resultados son mucho más honestos que una Normal aplicada donde no corresponde.
Deja una respuesta