
El departamento que no olvidaba.
Imagina un departamento universitario modélico, de una universidad centenaria y con lustre. Tiene presupuesto de investigación —variable x₁—, consume café en cantidades razonablemente escandalosas —variable x₂—, y produce artículos científicos en proporción a ambas cosas. La relación es estable y regular:
yₜ = 20 + 0.8·x1ₜ + 1.5·x2ₜ + εₜ
El problema surge con εₜ, la perturbación aleatoria. En series temporales, ese término de error no siempre se comporta como un sorteo independiente en cada periodo. A veces recuerda: si el año pasado fue malo, este año también tiende a serlo un poco. En términos técnicos, el error sigue un proceso autorregresivo de orden 1 —AR(1)—:
εₜ = ρ·εₜ₋₁ + uₜ, uₜ ~ N(0, σ²)
El parámetro ρ (rho) mide cuánto recuerda el error. Si ρ = 0, el error no tiene memoria: cada año es un mundo aparte. Si ρ = 0.85, el error de este año está muy condicionado por el del año anterior —como un departamento al que le cuesta olvidar los disgustos del curso pasado. Es el efecto «bola de nieve».
La pregunta que este post quiere responder es aparentemente sencilla; pero esconde una trampa clásica: ¿qué es peor, ignorar la autocorrelación cuando existe, o corregirla cuando no existe? Ambas son opciones equivocadas, pero sus consecuencias son asimétricas. Y esa asimetría es exactamente lo que vamos a explorar.
Lo que dice la teoría.
El estimador de Mínimos Cuadrados Ordinarios (MCO) tiene una propiedad notable: es insesgado incluso cuando los errores están autocorrelacionados. El problema no es que se equivoque sistemáticamente —en promedio apunta al valor correcto—, sino que es ineficiente: su dispersión entre muestras es mayor de lo necesario (imprecisión, lo que quiere decir que, para nuestra muestra de datos concreta, tenemos más riesgo de que nuestro estimador se quede «lejos» de verdadero parámetro poblacional, desconocido, al que intenta representar.
Pero hay algo más grave que la ineficiencia: cuando los errores están autocorrelacionados y se aplica MCO, los errores estándar reportados por el modelo están sesgados a la baja. El modelo subestima sistemáticamente su propia incertidumbre. Los estadísticos t se inflan artificialmente y se rechazan hipótesis nulas que no deberían rechazarse. El modelo ve significación donde quizás no la hay.
El modelo GLS-AR(1) —Mínimos Cuadrados Generalizados con estructura autorregresiva de orden 1— fue diseñado precisamente para este caso. Al incorporar la estructura del error en la estimación, recupera eficiencia y produce errores estándar bien calibrados. ¿Y cuando se aplica GLS innecesariamente? La teoría predice una ligera pérdida de eficiencia al estimar un parámetro ρ adicional que en realidad es cero, pero sin sesgar los estimadores. En resumen: ignorar la autocorrelación real es un error más grave que corregir una autocorrelación inexistente. Los datos van a confirmarlo.
El experimento de simulación.
El diseño es deliberadamente limpio. Generamos 1.000 muestras artificiales de T = 80 observaciones anuales para el modelo del departamento, reservando 20 observaciones adicionales para medir el error de predicción fuera de muestra. En cada muestra estimamos dos modelos: MCO clásico y GLS-AR(1) mediante máxima verosimilitud (función gls() del paquete nlme de R).
El experimento se repite en dos escenarios simétricamente opuestos:
- Experimento 1 — AR(1) fuerte (ρ = 0.85): la perturbación tiene memoria larga. El error de un año condiciona fuertemente el del siguiente. Es el caso donde la autocorrelación existe, importa y MCO debería sufrir las consecuencias. Great ball of… snow.
- Experimento 2 — Ruido blanco (ρ = 0.05): los errores son prácticamente independientes entre sí. No hay autocorrelación real. Es el caso donde aplicar GLS-AR(1) es innecesario —y potencialmente contraproducente—.
Para cada simulación registramos: la media de los estimadores, el error porcentual respecto al valor verdadero (medida del sesgo), el error estándar (SE) entre muestras —la dispersión real del estimador a lo largo de las 1.000 repeticiones—, el SE medio reportado por el modelo —lo que el modelo cree que es su precisión, que suele venir integrado, para cada estimador, en los resultados de la estimación—, el error porcentual entre ambos SE (la comparación clave), la tasa de rechazo del contraste t, y el error absoluto medio (MAE) de predicción fuera de muestra.
Las variables explicativas se generaron como caminatas aleatorias con deriva (cumsum()), que produce series con tendencia suave y variabilidad interanual similar a datos anuales reales. Los errores se generaron con la varianza estacionaria correcta para el proceso AR(1) en t = 1.
Resultados.
Experimento 1: el precio de ignorar la autocorrelación (ρ = 0.85).
La tabla 1 recoge los resultados completos del primer experimento.
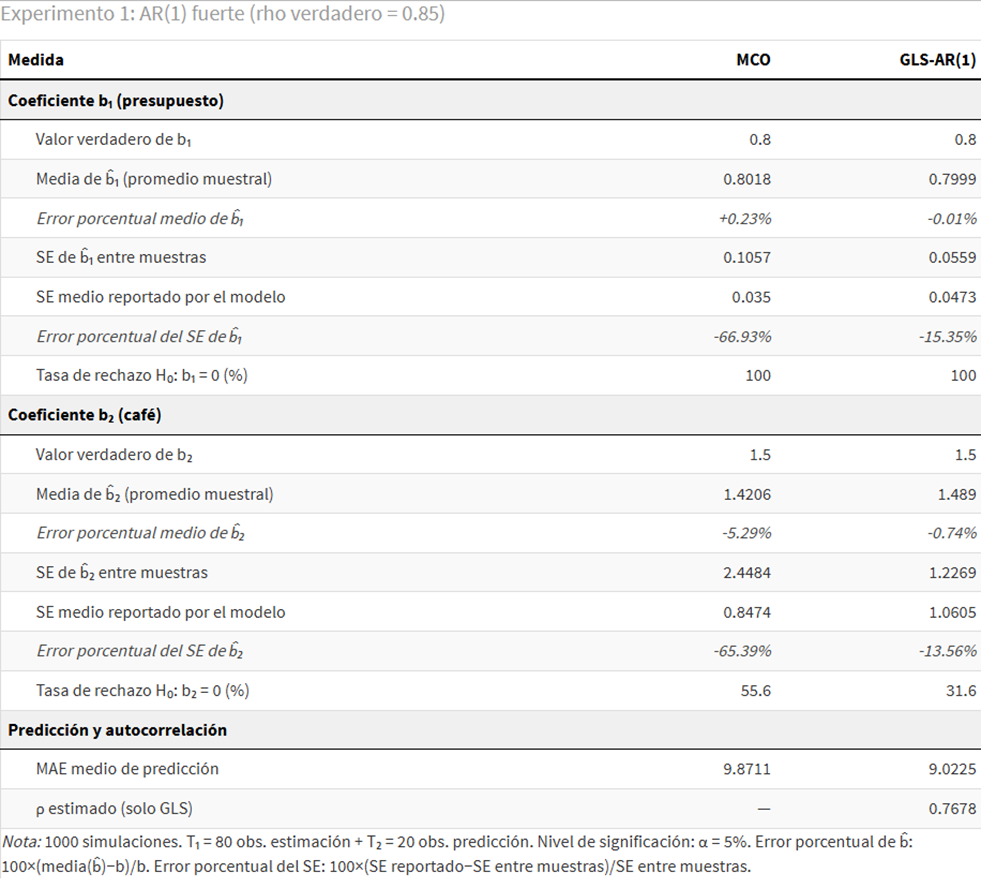
El primer resultado es el que la teoría ya anticipaba: los estimadores de MCO no están sesgados. La media de b̂₁ es 0.8018 (error porcentual +0.23%) y la de b̂₂ es 1.421 (error −5.3%). GLS tampoco sesga de modo apreciable. Ambos métodos apuntan al valor verdadero en promedio. Hasta aquí, nadie pierde.
El verdadero problema está en la dispersión. El SE de b̂₁ entre muestras es 0.1057 con MCO frente a 0.0559 con GLS: GLS es casi el doble de preciso. Con b̂₂ la diferencia es aún mayor: 2.4484 frente a 1.2269.
Pero el problema más grave no es la ineficiencia, sino lo que ocurre con los errores estándar que el modelo reporta. El SE medio reportado por MCO para b̂₁ es apenas 0.035, cuando la dispersión real entre muestras es 0.1057. El error porcentual es −66.9%: MCO subestima su propia incertidumbre en dos tercios. Para b̂₂ la situación es prácticamente idéntica: −65.4%. El modelo no solo es impreciso; además no lo sabe.
La consecuencia directa es la inflación de la significación estadística. La tasa de rechazo de H₀: b₂ = 0 es del 55.6% con MCO frente al 31.6% con GLS. MCO detecta el efecto del café con una confianza que no ha ganado.
En cuanto a la predicción fuera de muestra, el MAE medio es 9.871 con MCO y 9.023 con GLS, una mejora del 8.6% a favor del modelo bien especificado. La ganancia es real pero modesta: el principal coste de ignorar la autocorrelación es inferencial, no predictivo.
Experimento 2: el coste de corregir lo que no necesita corrección (ρ = 0.05).
La tabla 2 presenta los resultados del segundo experimento, donde la perturbación es prácticamente ruido blanco y se aplica igualmente GLS-AR(1).
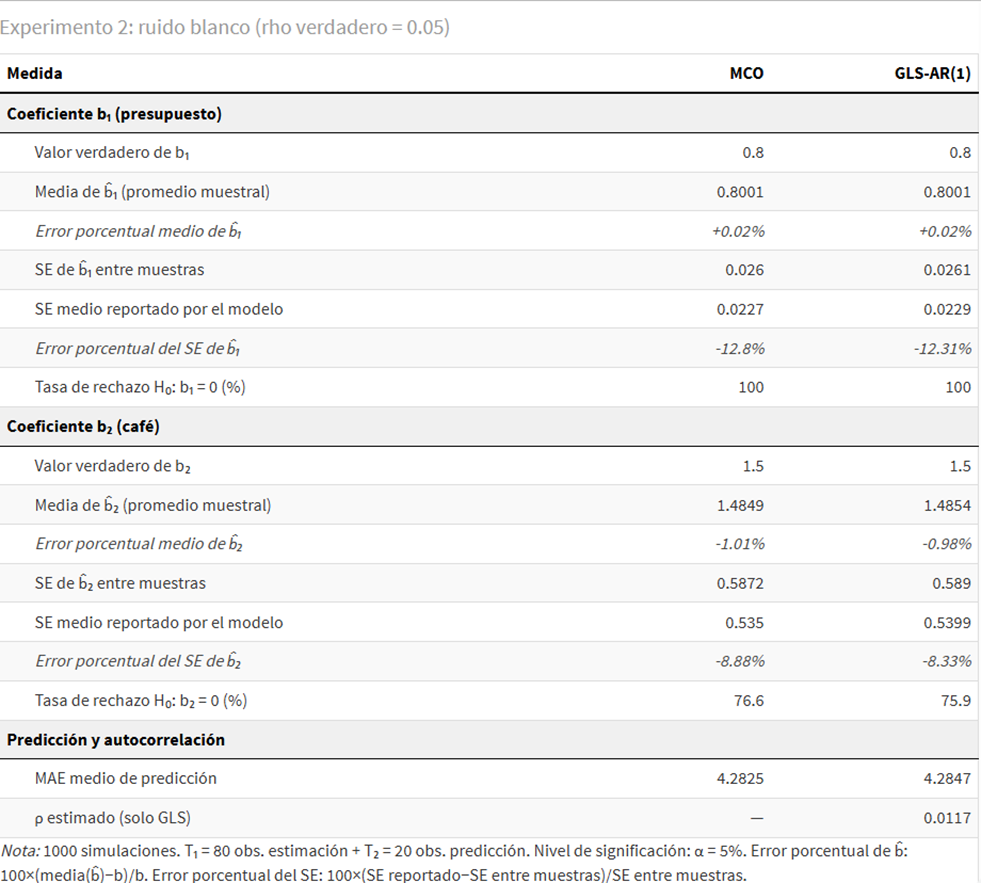
El cambio de escenario es radical. Ningún método sesga los estimadores: los errores porcentuales rondan el 1% o menos para ambos coeficientes. Y la dispersión de los estimadores es prácticamente idéntica entre métodos: SE de b̂₁ entre muestras de 0.026 con MCO y 0.0261 con GLS. Sin autocorrelación real, GLS no mejora la eficiencia, pero tampoco la empeora.
Lo más llamativo es la simetría en los errores porcentuales del SE reportado: −12.8% para MCO y −12.3% para GLS en b̂₁; −8.9% y −8.3% en b̂₂. Aplicar GLS innecesariamente no produce una distorsión adicional relevante en la calibración del SE: ambos métodos se equivocan por igual.
En predicción, los MAE son indistinguibles: 4.283 con MCO y 4.285 con GLS. El coste de una corrección innecesaria es más bien pequeño. El motivo: GLS estima ρ = 0.012, prácticamente cero. El modelo reconoce que no había enfermedad y aplica una corrección mínima.
En síntesis: el coste de una corrección innecesaria es mínimo. No es gratis —hay una ligera subestimación del SE que también afecta a MCO—, pero sus efectos son tan similares entre métodos que resultan difíciles de distinguir en la práctica.
Ahora bien, hemos de matizar este resultado, ya que el contexto en el que nos movemos es de muestras de 80 observaciones. En un marco de muestras pequeñas, como suele ocurrir con cierta frecuencia —modelos de no más de 20 datos anuales, por ejemplo—, el coste de incluir un parámetro a estimar adicional podría ser más evidente (lo que penalizaría medidas de bondad como el AIC).
Una lectura comparativa: qué nos dicen las figuras.
Las figuras que siguen permiten visualizar, de forma conjunta, las diferencias entre los dos experimentos y los dos métodos de estimación —MCO vs GLS con esquema AR(1)— en cada dimensión del análisis. Su lectura comparativa —izquierda vs. derecha, Experimento 1 vs. Experimento 2— es la síntesis más directa del experimento.
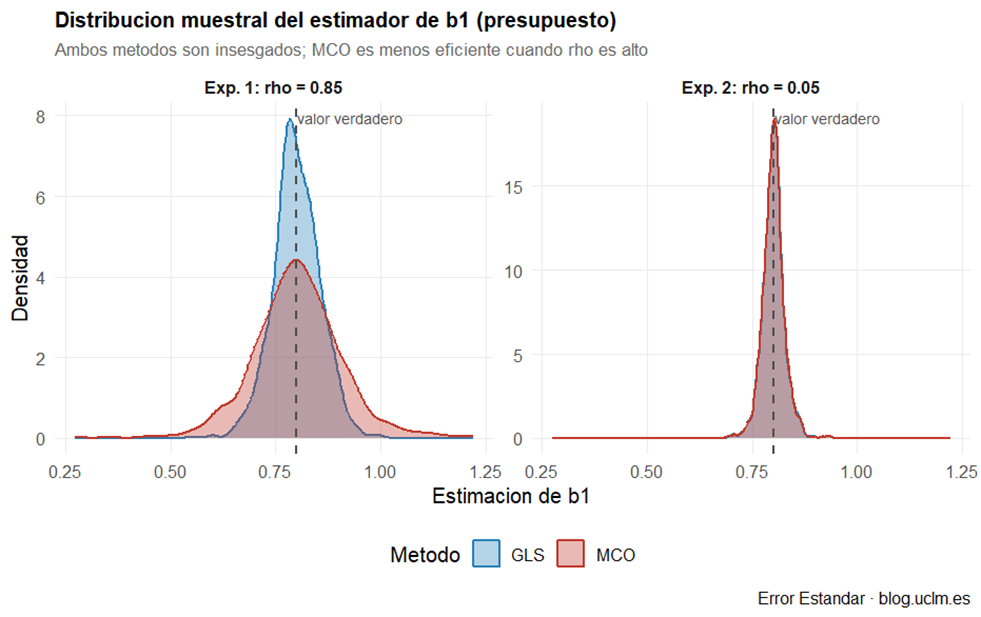
Figura 1
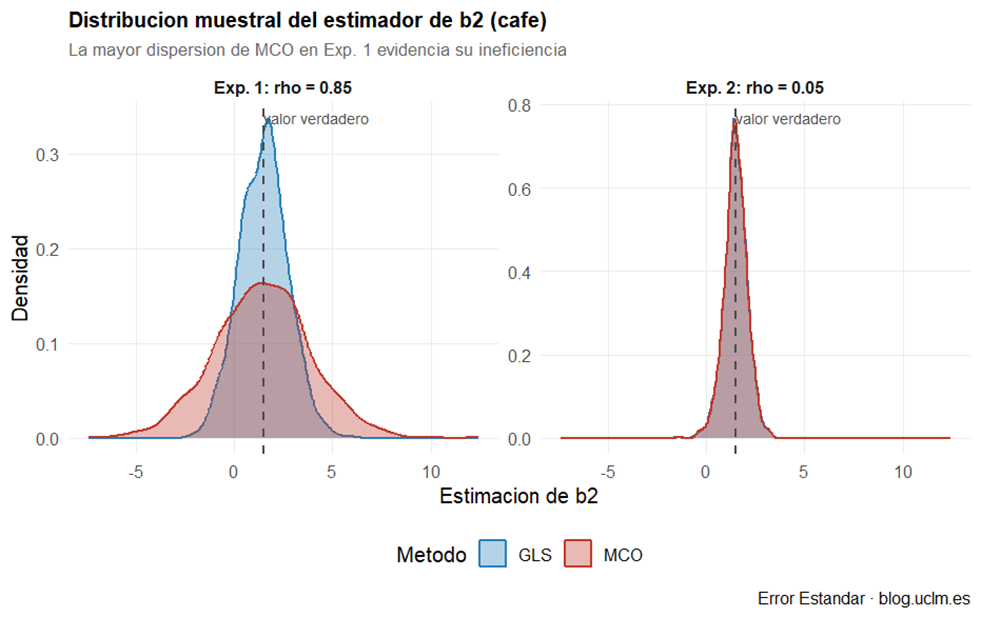
Figura 2
Dispersión de los estimadores (figuras 1 y 2). En el Experimento 1, la distribución de MCO es notablemente más ancha que la de GLS: los estimadores de MCO vagan mucho más alrededor del valor verdadero. En b̂₂ la diferencia es especialmente llamativa —la cola izquierda de MCO alcanza valores negativos del todo implausibles para el efecto del café—. En el Experimento 2, las curvas de ambos métodos son prácticamente indistinguibles: sin autocorrelación, la ventaja de GLS desaparece.
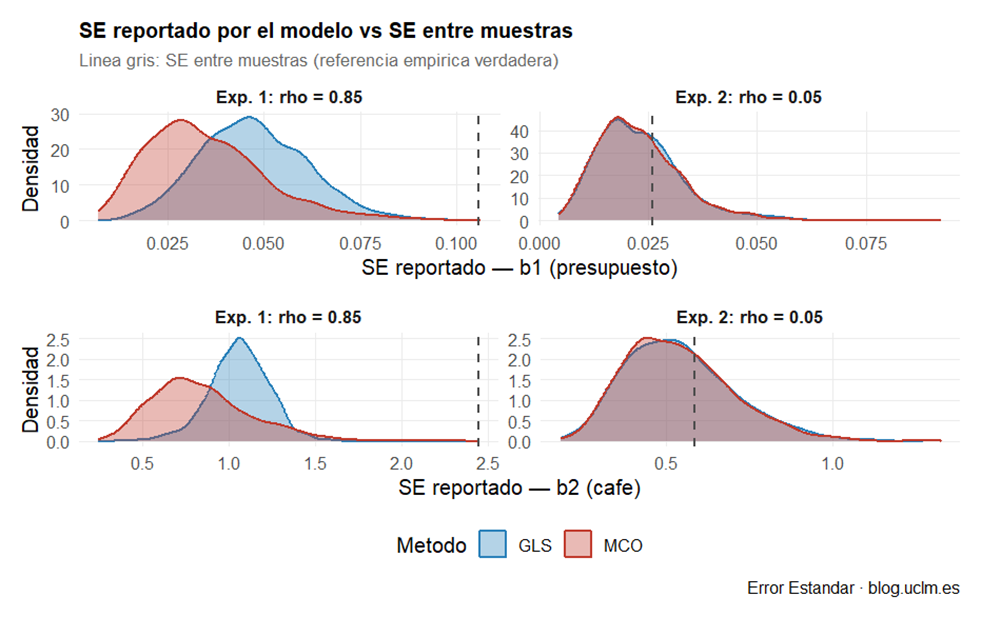
Figura 3
Error estándar reportado frente al SE entre muestras (figura 3). La figura 3 confronta lo que cada modelo reporta como SE con la dispersión real —la línea gris de referencia—. En el Experimento 1, la densidad de MCO queda muy a la izquierda de la referencia en ambas variables: subestimación sistemática y severa. GLS también subestima, pero de forma mucho más moderada. En el Experimento 2, ambas densidades se aproximan razonablemente a la referencia y son casi idénticas entre sí.
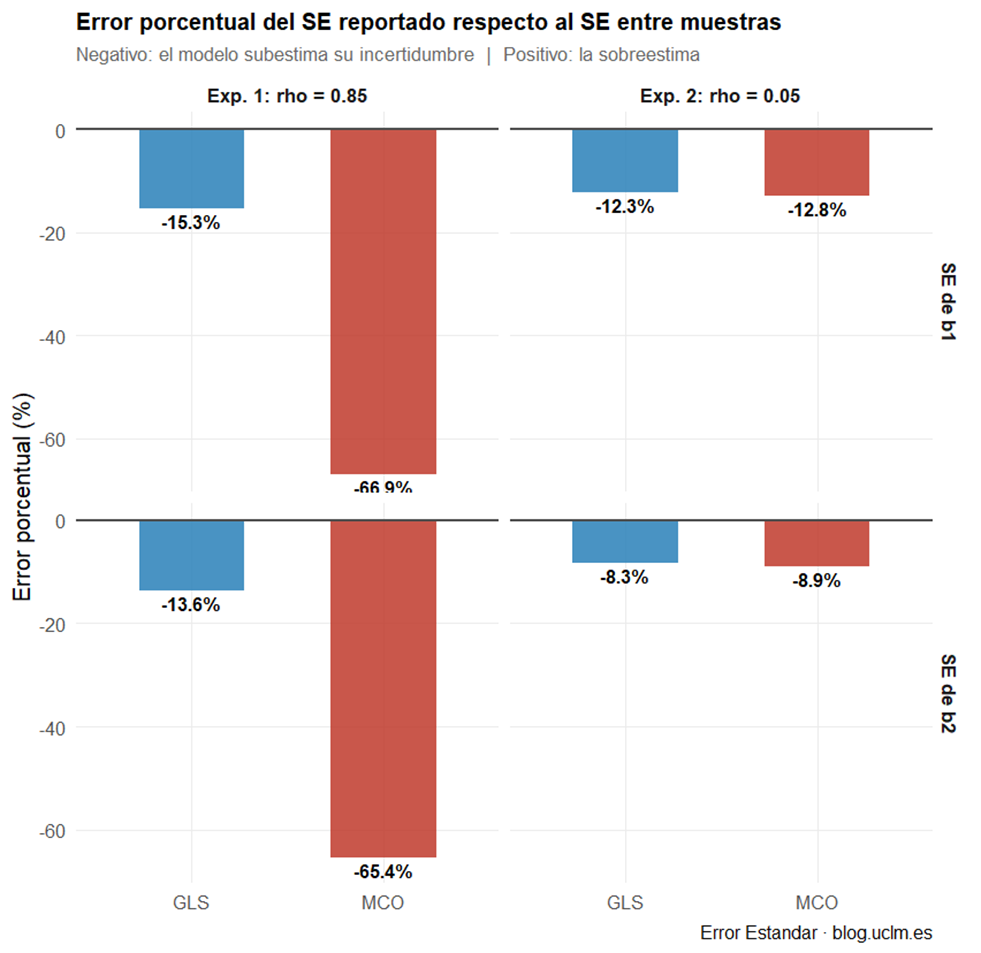
Figura 4
Error porcentual del SE (figura 4). La figura 4 resume en un único gráfico de barras la magnitud de la subestimación. En el Experimento 1, las barras de MCO alcanzan el −66.9% (b₁) y −65.4% (b₂): el modelo reporta un error estándar que es apenas un tercio de lo que debería ser. GLS subestima en torno al −15%, un error muy inferior. En el Experimento 2 la diferencia entre métodos desaparece: ambos rondan el −10%, sin ninguna desventaja sistemática.
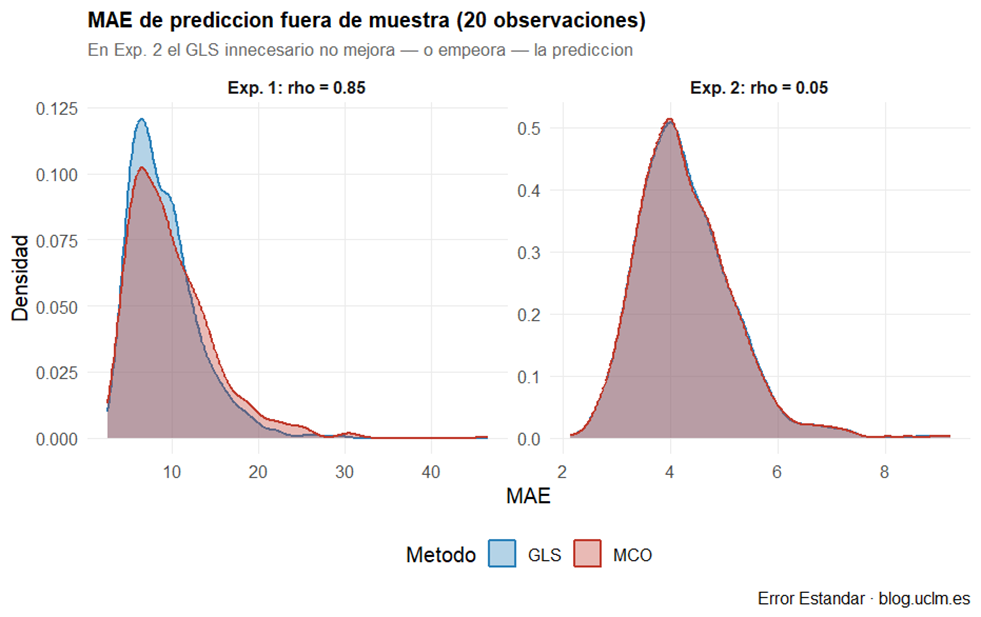
Figura 5
MAE de predicción fuera de muestra (figura 5). En el Experimento 1, la distribución del MAE de GLS está desplazada hacia la izquierda respecto a la de MCO: GLS predice mejor, aunque la ganancia sea modesta. En el Experimento 2, las dos distribuciones se solapan casi perfectamente: no hay ventaja de ningún método cuando el error es ruido blanco.
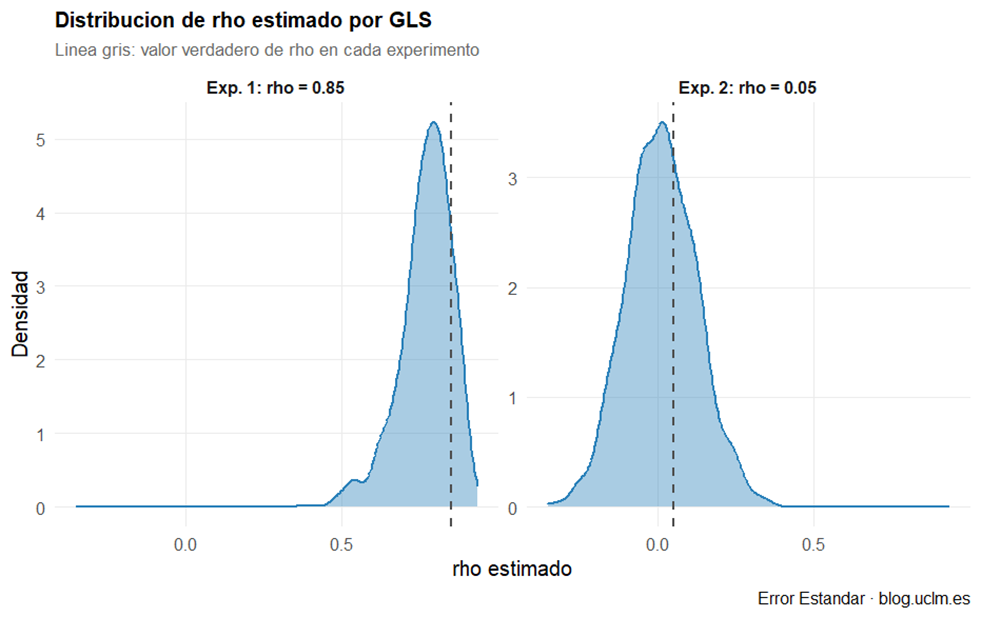
Figura 6
Distribución del ρ estimado por GLS (figura 6). Esta figura actúa como control de calidad del experimento. En el Experimento 1, GLS estima ρ ≈ 0.768 (el valor verdadero es 0.85; el sesgo hacia abajo es esperable en muestras finitas). En el Experimento 2, la masa se concentra cerca de cero: el modelo reconoce que no hay autocorrelación real y ajusta su corrección en consecuencia. El estimador de ρ funciona como un termómetro del problema.
En conclusión…
Los resultados permiten trazar un diagnóstico claro, aunque con un matiz importante que conviene no pasar por alto.
Cuando la autocorrelación existe y se ignora (Experimento 1): MCO produce estimadores insesgados pero ineficientes. Pero el problema más grave es que el modelo no lo sabe: subestima su propia incertidumbre en cerca de un 67%, infla los estadísticos t y genera una falsa sensación de significación estadística. La predicción también empeora, aunque de forma más modesta.
Cuando no hay autocorrelación y se aplica GLS (Experimento 2): los estimadores permanecen insesgados, la eficiencia no se deteriora, la calibración del SE es similar a la de MCO, y el MAE de predicción es prácticamente idéntico. El coste de una corrección innecesaria es sorprendentemente pequeño.
La asimetría que predice la teoría se confirma con claridad: ignorar la autocorrelación es mucho más dañino que corregirla innecesariamente, especialmente desde el punto de vista de la inferencia. El error de omisión es sistémico e invisible; el error de comisión es limitado y auto-diagnosticable.
Lecciones para llevar a casa.
- La insesgadez no es suficiente. MCO es insesgado con autocorrelación, pero eso no lo hace fiable para la inferencia. Lo que importa no es solo que el estimador apunte al blanco en promedio, sino que el modelo sepa cuánto se aleja del blanco en cada muestra individual. Y MCO, con autocorrelación fuerte, no lo sabe.
- El error estándar reportado puede mentir. Un SE artificialmente pequeño produce estadísticos t artificialmente grandes. Si el modelo subestima su incertidumbre en un 67%, el contraste t equivale a exigir solo un tercio de la evidencia necesaria para rechazar la hipótesis nula. Eso no es rigor estadístico: es optimismo estructural.
- Diagnosticar antes de corregir. El test de Durbin-Watson y sus variantes modernas —Breusch-Godfrey, entre otros— permiten detectar autocorrelación antes de decidir qué modelo estimar. No hay que aplicar GLS por defecto en cualquier serie temporal, pero tampoco ignorar el problema porque el modelo converge bien.
- El ρ estimado es un termómetro. GLS-AR(1) estima ρ como parte del proceso. Un ρ estimado cercano a cero es la propia señal de que la corrección era innecesaria. Si el remedio dice que no había enfermedad, conviene revisitar el diagnóstico inicial.
- La predicción es el juez más severo. La diferencia en MAE entre MCO y GLS en el Experimento 1 es real pero modesta (8.6%). El principal coste de ignorar la autocorrelación es inferencial, no predictivo. En aplicaciones donde la predicción sea el objetivo principal, GLS sigue siendo preferible, pero no drásticamente superior.
- El café sigue siendo significativo. Con MCO, la tasa de rechazo de H₀: b₂ = 0 es del 55.6% frente al 31.6% con GLS. Ambos métodos encuentran evidencia del efecto del café, pero MCO lo hace con una confianza que no ha ganado. Un revisor sagaz preguntará por qué el SE es tan pequeño. La respuesta honesta, con MCO y autocorrelación fuerte, es que el modelo no se lo merece.
(*) Nota técnica.
El experimento se realizó en R con 1.000 simulaciones por escenario. Las variables explicativas se generaron como caminatas aleatorias con deriva (cumsum()). Los errores se generaron con la varianza estacionaria correcta para el proceso AR(1) en t = 1. El modelo GLS se estimó con la función gls() del paquete nlme, usando estructura de correlación corAR1() y máxima verosimilitud. La predicción fuera de muestra es ex ante pura: solo se usan los valores de x₁ y x₂ en el periodo de predicción, sin aprovechar el último residuo observado.
Deja una respuesta