
Al sol que más calienta.
El Instituto Nacional de Estadística de Sunlandia —conocido en los pasillos como el INES, aunque nadie se pone de acuerdo en si es masculino o femenino— lleva meses trabajando en un estudio sobre la implantación de energía fotovoltaica a nivel municipal. El objetivo es ambicioso: entender qué factores explican que unos municipios instalen muchos más paneles solares por habitante que otros. La variable dependiente es la potencia fotovoltaica instalada, medida en vatios por cada mil habitantes (W/1.000 hab.), y los datos cubren una muestra de 200 municipios de Sunlandia.
El problema empieza, como casi siempre, antes de tocar los datos. El analista ha de decidir qué variables entran en el modelo y cuáles quedan fuera. Y aquí es donde el INES, fiel a su tradición de generar tres versiones de cada informe según quién haya llegado antes a la oficina esa mañana, produce tres especificaciones distintas.
Este post estudia, mediante simulación Monte Carlo, qué consecuencias tiene cada decisión de especificación. La conclusión adelantada es que los dos tipos de error no son en absoluto simétricos: omitir una variable relevante es mucho más dañino que incluir una irrelevante.
El fenómeno verdadero y los tres modelos de INES.
Lo bueno de realizar un experimento de simulación es que nosotros conocemos el modelo que genera los datos —el proceso generador de datos o DGP—. Por lo tanto, nos permitimos el lujo de saber cómo funcionan los fenómenos, ya que nosotros mismos los creamos. Así, la variable dependiente Y depende linealmente de dos variables:
Y = 50 + 8 · X₁ + 5 · X₂ + ε, ε ~ N(0, 30²)
donde X₁ son las horas de sol al año (en centenas; media ≈ 24, equivalente a 2.400 h anuales), X₂ es la renta media por hogar (en miles de euros; media ≈ 28, equivalente a 28.000 €), y ε es el término de error con desviación típica 30 W/1.000 hab.
Las unidades están elegidas para que los coeficientes sean legibles: β₁ = 8 significa que cien horas adicionales de sol al año se asocian a 8 W/1.000 hab. más de potencia instalada; β₂ = 5 implica que cada mil euros adicionales de renta media se asocian a 5 W/1.000 hab. adicionales.
Existe además una tercera variable, X₃, la altitud media en centenas de metros. Su coeficiente verdadero en el DGP es cero: no tiene ningún efecto causal. Sin embargo, resulta plausible a primera vista —más altura, más radiación, razonan los analistas optimistas—, lo que la convierte en candidata perfecta para ilustrar el error de inclusión indebida.
Un detalle crucial: X₁ y X₂ no son independientes. Los municipios más soleados de Sunlandia tienden a ser más cálidos, más turísticos y, en general, más ricos. La correlación entre horas de sol y renta media es ρ₁₂ = 0,60. Esta cifra será clave para entender el sesgo de omisión.
Los analistas de INES no tienen nuestra misma suerte, y por lo tanto han de proponer sus especificaciones del modelo alternativas, esperando quedarse lo suficientemente cerca de la explicación del fenómeno real como para poder ser asumida. Las especificaciones propuestas han sido 3:
- M0 (modelo correcto): Y ~ X₁ + X₂. El propuesto por el analista madrugador, que llega el primero y conoce la literatura.
- M1 (omisión de X₂): Y ~ X₁. El analista que olvidó pedir los datos de renta al departamento de Hacienda de Sunlandia.
- M2 (inclusión de X₃ irrelevante): Y ~ X₁ + X₂ + X₃. El analista entusiasta —pero inseguro— que añade la altitud «por si acaso».
Diseño de la simulación Monte Carlo.
Para evaluar las propiedades de los estimadores se recurre a la simulación Monte Carlo. La idea es sencilla: repetimos el experimento 5.000 veces. En cada réplica generamos una nueva muestra de municipios, estimamos los tres modelos y guardamos los resultados. Al cabo de 5.000 repeticiones tenemos una imagen completa del comportamiento estadístico de los estimadores. El experimento se repite para tres tamaños muestrales: n = 50, n = 200 y n = 500 municipios, lo que permite estudiar la consistencia de los estimadores. En cada réplica se generan también 40 municipios adicionales —fuera de la muestra de estimación— para evaluar la calidad predictiva de cada modelo.
Insesgadez y consistencia de
La primera pregunta es directa: ¿estima cada modelo correctamente el efecto de las horas de sol? La Figura 1 muestra la distribución muestral de para los tres modelos y los tres tamaños de muestra.
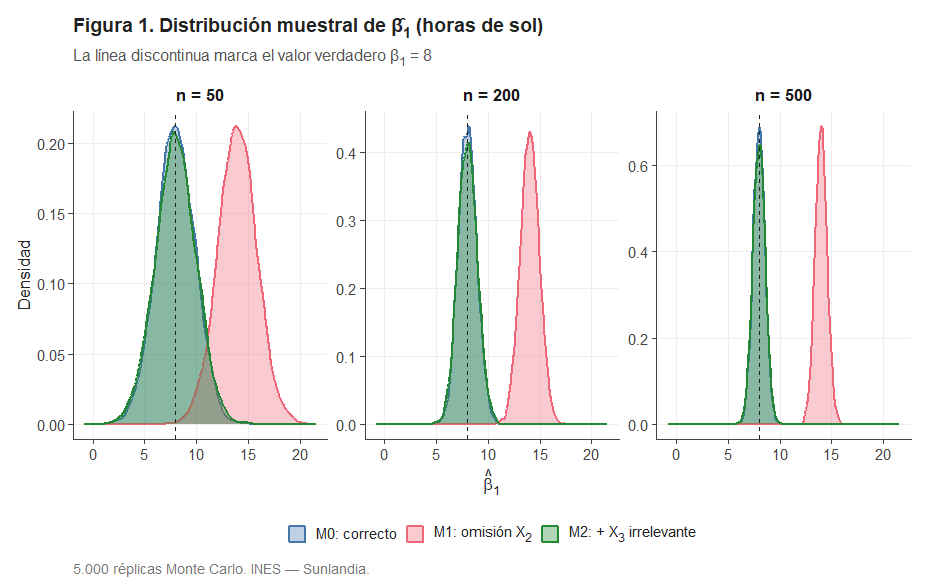
El resultado es inequívoco. M0 y M2 producen distribuciones perfectamente centradas en β₁ = 8: sus estimadores son insesgados. M1 desplaza toda la distribución hacia la derecha, acumulándose alrededor de 14. El estimador del efecto del sol sobreestima sistemáticamente en casi 6 unidades.
¿Por qué ese sesgo? Porque al excluir X₂ (renta), el modelo le «achaca» al sol parte del efecto que corresponde a la renta. Como los municipios más soleados también tienden a ser más ricos (ρ₁₂ = 0,60), el estimador de β₁ absorbe parte de β₂ y se infla. Este fenómeno se conoce como sesgo de variable omitida.
M2 se comporta exactamente igual que M0: incluir la altitud irrelevante no introduce ningún sesgo en La primera pregunta es directa: ¿estima cada modelo correctamente el efecto de las horas de sol? La Figura 1 muestra la distribución muestral de para los tres modelos y los tres tamaños de muestra. La Figura 2 y la Tabla 1 ilustran la consistencia de los estimadores.
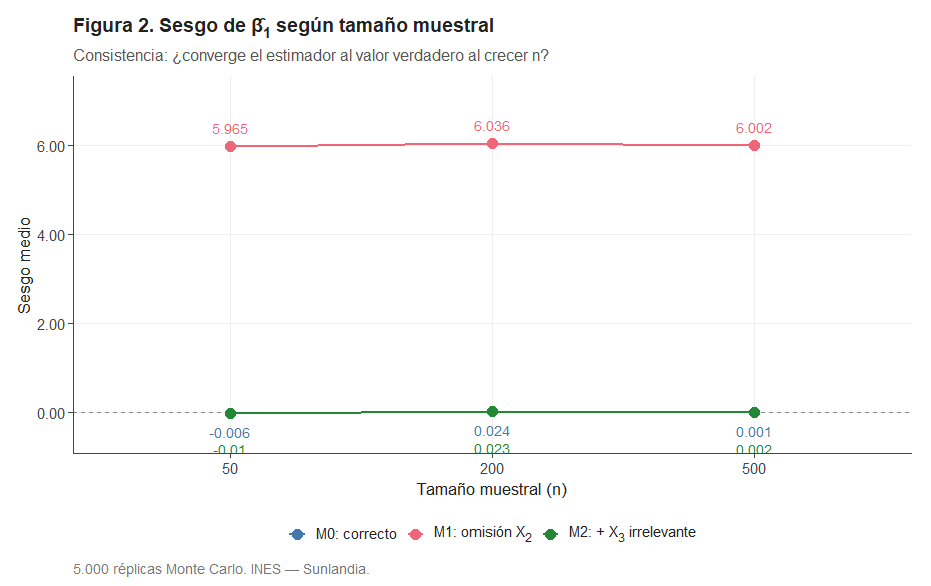
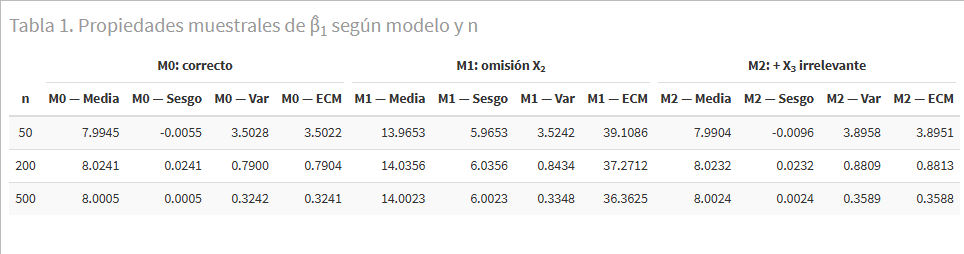
En M0 y M2, el sesgo es prácticamente nulo para cualquier n. En M1, el sesgo no solo es elevado: es estable. Aumentar la muestra de 50 a 500 municipios no lo reduce en absoluto. Esto es la definición de inconsistencia: el estimador no converge al valor verdadero aunque dispongamos de infinitos datos. La columna ECM —error cuadrático medio— de la Tabla 1 lo cuantifica: el ECM de en M1 es entre 40 y 100 veces mayor que en M0.
(*) Una nota sobre multicolinealidad. En M0, X₁ y X₂ presentan una correlación de ρ₁₂ = 0,60, lo que implica un VIF ≈ 1,56 para ambos regresores. Es una multicolinealidad débil, lejana de los umbrales habitualmente preocupantes (VIF > 5 ó > 10). No obstante, es precisamente esta correlación la que amplifica el sesgo de omisión en M1.
Eficiencia: ¿qué modelo malgasta información?
¿Cómo de dispersos son los estimadores? La Figura 3 muestra la varianza muestral de para los tres modelos en función de n.
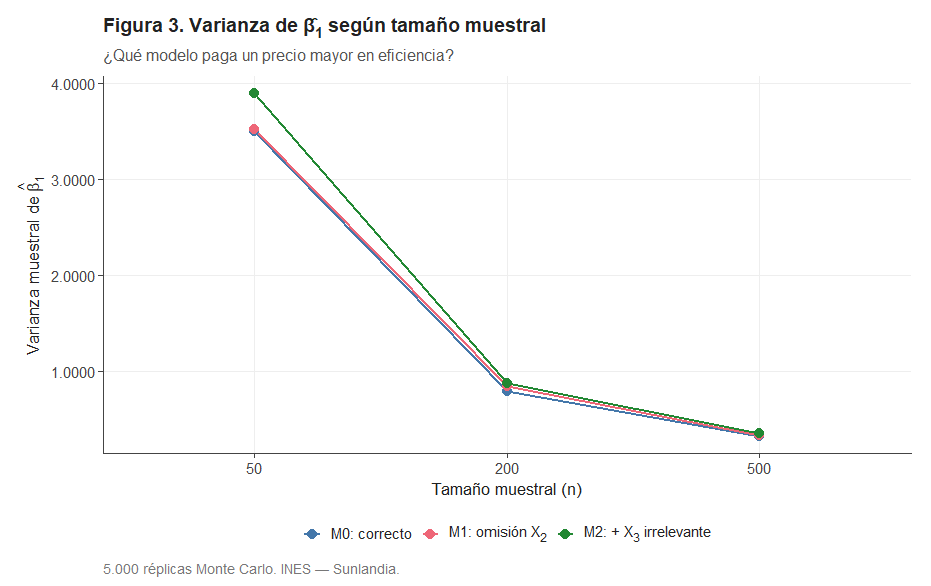
Los tres modelos convergen hacia cero al crecer n, pero el patrón relativo es revelador. M1 no es el más ineficiente en varianza: con un solo regresor, su estimador resulta algo menos variable que en los modelos con dos o tres regresores. Sin embargo, M1 tiene un sesgo contundente. El ECM (Varianza + Sesgo²) es la métrica que integra ambas dimensiones, y en esa métrica M1 pierde por goleada.
¿Qué pasa con el efecto de la renta?
La Figura 4 muestra la distribución de en M0 y M2 para n = 200.
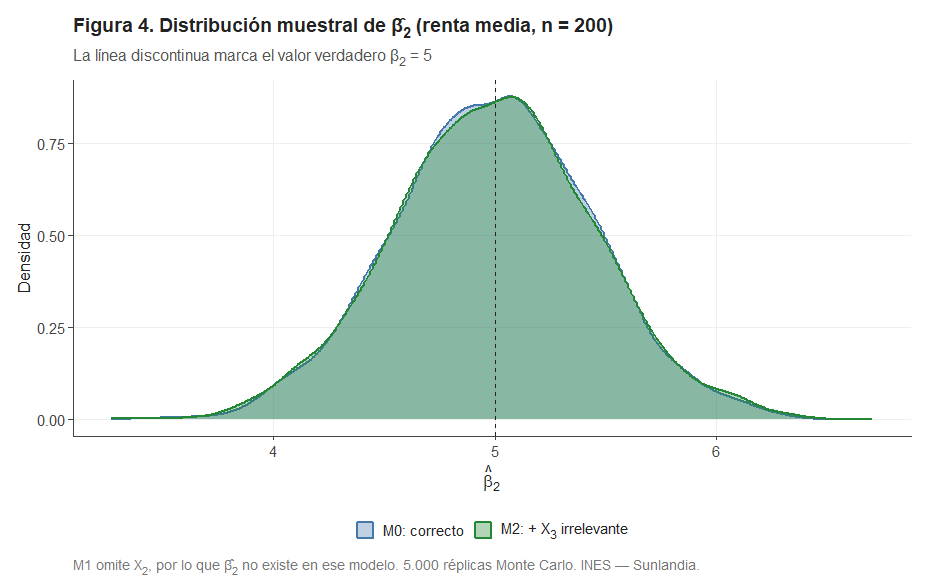
Incluir X₃ (irrelevante) no introduce ningún sesgo en La Figura 6 muestra la distribución de en M0 y M2 para n = 200.. Ambas distribuciones están centradas en el valor verdadero β₂ = 5 con dispersión prácticamente idéntica. M2 paga un peaje mínimo en eficiencia, pero no deteriora la estimación de los coeficientes relevantes. En M1, β₂ no existe: el efecto de la renta queda enterrado bajo el sol.
Bondad del ajuste: R² y AIC.
La Figura 5 muestra la distribución del R² y del AIC (Criterio de Información de Akaike) para los tres modelos con n = 200. El R² mide la proporción de varianza explicada (mayor es mejor); el AIC penaliza la complejidad del modelo (menor es mejor).
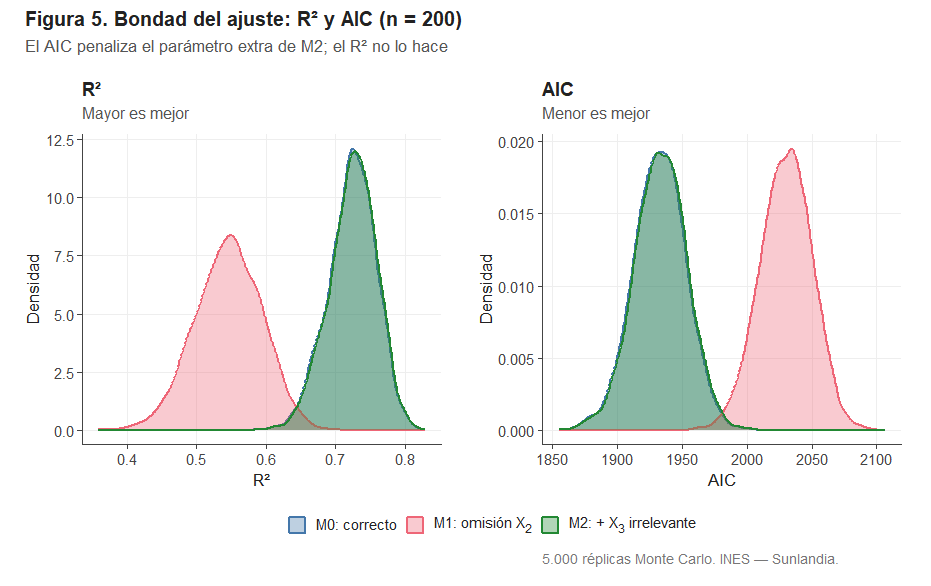
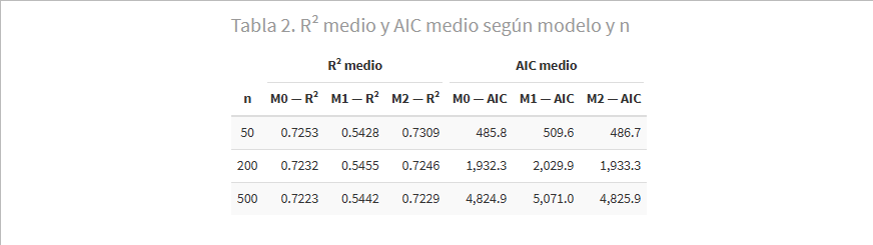
M1 muestra un R² sistemáticamente inferior (≈ 0,54 frente a ≈ 0,72 de M0): al omitir la renta pierde una parte sustancial del poder explicativo. M2 obtiene un R² prácticamente idéntico al de M0 —añadir una variable irrelevante nunca puede reducir el R², por construcción matemática—. El AIC, sin embargo, detecta el exceso de complejidad de M2 y le asigna un valor ligeramente peor que a M0. El AIC «sabe» que X₃ no añade información real; el R² no lo sabe.
Calidad predictiva fuera de muestra.
La prueba definitiva es la predicción sobre municipios no observados. En cada réplica se calculó el RMSE (Raíz del Error Cuadrático Medio, en W/1.000 hab.) sobre 40 municipios fuera de muestra.
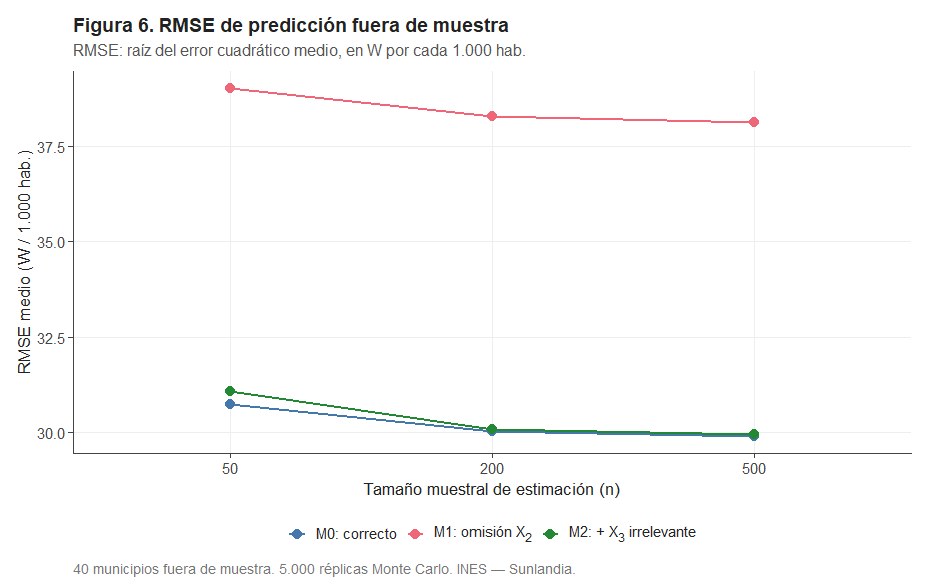
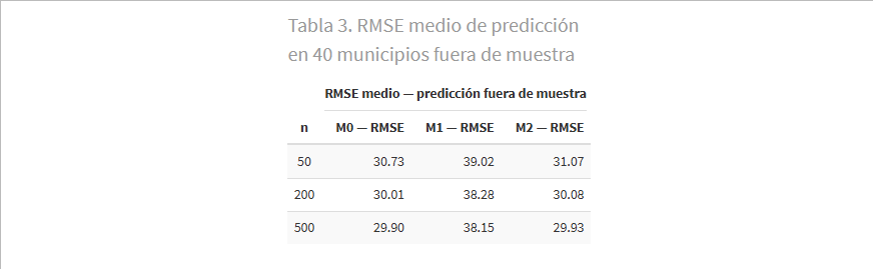
M1 produce errores de predicción de en torno a 38–39 W/1.000 hab., frente a los 30 W/1.000 hab. de M0: un 27% más. Y lo más llamativo: aumentar la muestra de 50 a 500 municipios apenas reduce el RMSE de M1. El sesgo no desaparece con más datos, y se paga directamente en la predicción. M2 es prácticamente indistinguible de M0 en términos predictivos.
Conclusiones.
La omisión de una variable relevante (M1) produce consecuencias en cascada: el estimador de es sesgado e inconsistente, el ECM es entre 40 y 100 veces mayor que en el modelo correcto, la bondad del ajuste se deteriora y la calidad predictiva empeora en un 27%.
La inclusión de una variable irrelevante (M2) produce consecuencias mucho más benignas: los estimadores se mantienen insesgados y consistentes, la varianza aumenta marginalmente y el AIC detecta el exceso de complejidad. La calidad predictiva es prácticamente idéntica a la del modelo correcto.
En resumen: omitir lo que importa destruye las propiedades del estimador. Incluir lo que sobra apenas le hace cosquillas. Esta asimetría es la razón por la que el análisis econométrico, a menudo, dedica más esfuerzo a justificar qué variables deben entrar en el modelo que a eliminar las que ya están.
Lecciones de INES.
El departamento de metodología del INES, tras revisar los tres informes, redactó el siguiente memorándum interno. Lo reproducimos con su permiso —y con alguna edición ortográfica—:
Omitir una variable relevante que está correlacionada con las incluidas sesga los estimadores de forma sistemática e incorregible. Más datos no ayudan. Una muestra de 500 municipios con un modelo mal especificado es menos útil que una de 50 con el modelo correcto.
- El sesgo de omisión no es universal: si la variable omitida es ortogonal a las incluidas, el estimador sigue siendo insesgado. El problema aparece cuando existe correlación entre ellas, lo cual es la norma en datos económicos y sociales.
- Incluir una variable irrelevante es un pecado menor. Los estimadores se mantienen insesgados y consistentes. El AIC puede detectar el exceso de complejidad; el R² nunca lo hará.
- La capacidad predictiva fuera de muestra es el juez más severo. M1 paga un peaje del 27% en RMSE que no se recupera aunque se multiplique el tamaño de la muestra.
- El Error Cuadrático Medio integra sesgo y varianza. Es la métrica adecuada para comparar estimadores con distinto sesgo y distinta varianza. La diferencia entre M0 y M1 es de uno a dos órdenes de magnitud.
- La multicolinealidad amplifica el sesgo de omisión. Con ρ₁₂ = 0,60 y un VIF de 1,56, el sesgo en β̂₁ ya representa el 75% del valor verdadero. A mayor correlación entre la variable omitida y las incluidas, mayor daño.
Bonus Track: nos parecemos (un poco), y por eso nos echamos tanto de menos…
El sesgo que introduce M1 al omitir X₂ no es una constante universal: depende del grado de correlación entre la variable omitida y las variables incluidas en el modelo. La expresión del sesgo teórico de cuando se omite X₂ es:
Sesgo() = β₂ · ρ₁₂ · (σ₂ / σ₁)
En nuestra simulación: β₂ = 5, ρ₁₂ = 0,60, σ₂ = 6 y σ₁ = 3, lo que da un sesgo teórico de 5 · 0,60 · (6/3) = 6. Exactamente lo que observamos en la Figura 2 y la Tabla 1.
La implicación es importante: si X₁ y X₂ fuesen ortogonales (ρ₁₂ = 0), omitir X₂ no produciría ningún sesgo en . Pero en la práctica, las variables económicas y sociales rara vez son ortogonales.
En nuestro caso, ρ₁₂ = 0,60 implica un VIF ≈ 1,56, una multicolinealidad débil en sí misma. Y sin embargo es suficiente para generar un sesgo de omisión del 75% del valor verdadero de β₁. La relación exacta entre el grado de multicolinealidad de la variable omitida con las incluidas y el tamaño del sesgo de omisión será objeto de un próximo post en Error Estándar.
Deja una respuesta