
Villarriba presume. Villabajo encarga un estudio.
Durante décadas, Villarriba y Villabajo se miran con recelo a través del río que las separa. El origen de la rivalidad, según los más viejos del lugar, fue un concurso de empanadas en 1987 cuyo resultado se discute aún hoy. Pero la última batalla no se libra en las fiestas patronales, sino en las estadísticas del mercado laboral.
El alcalde de Villarriba lleva meses presumiendo en todos los foros de que los salarios de su municipio son superiores a los de Villabajo. Y lo hace con mala intención, porque en esa zona del país el salario medio se toma como termino de prosperidad y calidad de vida: quien cobra más, vive mejor. Villabajo, herido en su orgullo colectivo, no puede quedarse sin responder. Su alcalde decide encargar un estudio para demostrar que la diferencia salarial es inexistente, que los empadronados en su municipio cobran, en media, lo mismo que los de Villarriba, que son igual de prósperos y que la empanada de 1987 la ganó con toda justicia.
El planteamiento del estudio es el siguiente. Se toman muestras aleatorias de trabajadores de cada municipio, se calcula el salario medio en cada grupo y se somete la diferencia observada a un contraste de hipótesis. La hipótesis nula (H₀) es la posición de Villabajo: los salarios medios son iguales en ambos municipios. La hipótesis alternativa (H₁) es lo que teme Villabajo y proclama Villarriba: el salario medio en Villarriba es superior. Si el contraste concluye que los datos son incompatibles con H₀, Villabajo tendrá que admitirlo y sus ciudadanos y alcalde, mirar al suelo compungidos. Si no lo hace, el alcalde de Villabajo celebrará el resultado con empanada.
A lo largo de este post vamos a usar ese escenario para entender qué es exactamente el p-valor, qué mide, qué no mide, y por qué es uno de los conceptos más malinterpretados de toda la estadística aplicada. Pero antes de llegar al p-valor hay que sentar las bases: qué distribución siguen las diferencias salariales que vamos a calcular, y por qué se tipifica.
Del euro al estadístico: por qué hablamos de 1, 2 y 3,2 en lugar de euros.
Supongamos que los salarios individuales en cada municipio siguen una distribución normal con una desviación típica σ conocida. En nuestro experimento, σ = 1.000 euros y el salario medio base es de 25.000 euros anuales. Tomamos muestras de tamaño n en cada municipio y calculamos la diferencia entre las dos medias muestrales.
Esa diferencia de medias —llamada X̄B − X̄A— es a su vez una variable aleatoria. Y gracias al teorema central del límite, sabemos exactamente qué distribución tiene: una distribución normal, con media igual a la diferencia real de medias poblacionales (μB − μA) y desviación típica igual a σ√(2/n). Con σ = 1.000 euros y n = 100 por grupo,esa desviación típica vale 141 euros: la diferencia de medias muestrales fluctuará en torno a la diferencia real con una desviación típica de 141 euros, aunque los salarios de ambos municipios sean idénticos.
Para poder trabajar con una sola distribución de referencia —independientemente de los euros, el tamaño muestral o la desviación típica particular de cada problema—, se tipifica la diferencia: se le resta su media bajo H₀ (que es cero, porque bajo H₀ asumimos μB − μA = 0) y se divide por la desviación típica calculada anteriormente. El resultado es el estadístico de contraste Z, que bajo H₀ sigue exactamente una distribución normal tipificada N(0,1): media cero y desviación típica uno. Por eso en las figuras el eje horizontal muestra valores como −3, 0, 1, 2… y no euros: son diferencias de medias expresadas en unidades del error estándar.
Cuando H₀ es falsa —es decir, cuando los salarios de Villarriba sí son superiores—, el estadístico Z ya no tiene media cero. Su media es el parámetro de no centralidad δ, que mide la diferencia real entre medias poblacionales en unidades del error estándar: δ = (μA − μB) / (σ√(2/n)). Si Villarriba cobra en media 141 euros más que Villabajo y el error estándar es de 141 euros, δ = 1. Si la diferencia real es 282 euros, δ = 2. Y así sucesivamente. δ es, en esencia, el tamaño del efecto en escala tipificada: cuántas desviaciones típicas del estadístico separa la realidad de lo que predice H₀.
Con este marco, el contraste se reduce a una pregunta sencilla: dado el valor de Z que hemos observado en nuestra muestra, ¿es plausible que proceda de una normal tipificada N(0,1)? Si la respuesta es sí, los datos son compatibles con H₀ y Villabajo puede respirar. Si la respuesta es no, los datos sugieren que Z viene de una distribución desplazada —que hay una diferencia real— y Villabajo tiene un problema.
El p-valor: la pregunta específica que responde.
Una vez calculado el estadístico Z a partir de los datos, el p-valor es la probabilidad de obtener un valor tan extremo como el observado, o más, suponiendo que H₀ es verdadera. En nuestro contraste unilateral derecho, donde H₁ dice que Villarriba cobra más, «tanto o más extremo» significa «tanto o más grande»: el p-valor es el área a la derecha de Z bajo la curva de la normal tipificada N(0,1).
Si esa área es pequeña —menor que el nivel de significación α, convencionalmente 0,05—, concluimos que lo observado sería muy poco probable si H₀ fuera cierta y, por tanto, rechazamos H₀. Si el área es grande, los datos son perfectamente compatibles con H₀ y no hay evidencia suficiente para rechazarla. Villabajo puede relajarse, al menos hasta el próximo estudio.
La definición precisa importa porque los errores de interpretación son enormemente frecuentes, incluso entre investigadores con experiencia. El p-valor no es la probabilidad de que H₀ sea verdadera. El cálculo asume que H₀ es verdadera desde el principio; lo que mide es lo sorprendentes que serían los datos en ese caso. Es P(datos | H₀), no P(H₀ | datos). Confundir ambas cosas —tomar el p-valor como si midiera la probabilidad de que la hipótesis sea cierta o falsa— es uno de los errores más comunes y consecuentes de la práctica estadística diaria.
El p-valor tampoco mide la importancia práctica del efecto: un p-valor de 0,001 no dice que la diferencia salarial sea grande, dice que sería muy raro obtener esos datos si no hubiera ninguna diferencia. La magnitud del efecto y su relevancia práctica son preguntas distintas que requieren herramientas distintas. Y, por último, el umbral 0,05 es una convención heredada de la práctica del siglo XX, no una ley de la naturaleza: un p = 0,049 y un p = 0,051 son prácticamente indistinguibles, aunque uno «signifique» y el otro no.
Ver para creer: H₀ y H₁ en el mismo gráfico.
. La Figura 1 es el gráfico que debería aparecer en todos los manuales de estadística y que casi ninguno incluye con suficiente claridad. Muestra, para tres tamaños de efecto distintos (δ = 1, 2 y 3,2), cómo se distribuye el estadístico Z bajo H₀ y bajo H₁, y dónde quedan todas las piezas del contraste.
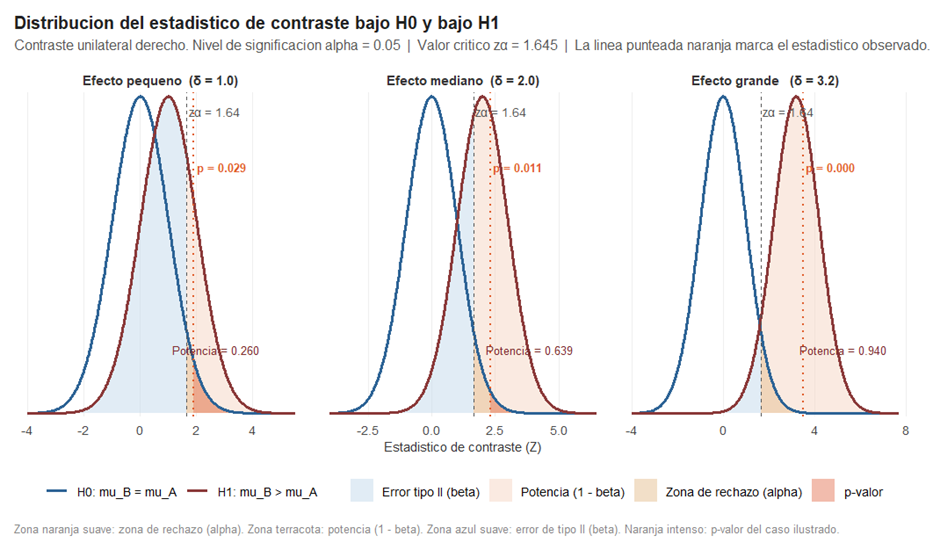
La curva azul es la distribución N(0,1) tipificada que predice H₀: si los salarios fueran iguales en ambos municipios, los valores de Z que obtendríamos en distintas muestras se distribuirían así, centrados en cero. La curva terracota es la distribución del estadístico cuando H₁ es verdadera, es decir, cuando Villarriba cobra realmente más: está desplazada δ unidades hacia la derecha, donde δ es la diferencia real expresada en unidades del error estándar.
La línea vertical discontinua es el valor crítico zα = 1,645: todo lo que caiga a su derecha bajo la curva azul constituye la región de rechazo. El área de la curva azul en esa región es exactamente α = 0,05. Eso significa que si los salarios fueran realmente iguales, el 5% de las muestras posibles producirían un Z tan grande que llevaría a rechazar H₀ equivocadamente. Ese es el error de tipo I: la probabilidad de dar una falsa alarma, de decirle a Villabajo que sus salarios son inferiores cuando en realidad son iguales.
La línea punteada naranja es el valor de Z obtenido en el experimento concreto ilustrado en cada panel. El área de la curva azul a la derecha de esa línea es el p-valor: cuán probable sería obtener un Z tan grande o mayor si los salarios fueran iguales. Si esa área es menor que 0,05, rechazamos H₀.
Ahora miremos la curva terracota. El área a la derecha del valor crítico bajo H₁ es la potencia del contraste (1 − β): la probabilidad de rechazar H₀ cuando Villarriba realmente paga más, es decir, la probabilidad de detectar la diferencia si existe. El área a la izquierda del valor crítico bajo H₁ es el error de tipo II (β): la probabilidad de no detectar la diferencia aunque exista —el riesgo de que Villabajo salga absuelto cuando en realidad sus salarios sí son inferiores.
El efecto del tamaño del efecto δ es inmediato y muy visual. Con δ = 1 —las dos curvas apenas separadas— la potencia es solo del 26%: en tres de cada cuatro muestras no detectaríamos la diferencia aunque Villarriba cobrara realmente más. La zona azul suave (error tipo II) es enorme. Con δ = 3,2 la potencia llega al 94%: las dos curvas apenas se solapan y casi cualquier muestra detectaría la diferencia. La enseñanza es directa: no rechazar H₀ no significa que H₀ sea verdadera. Puede significar simplemente que δ es pequeño y el contraste no tiene suficiente potencia para detectarlo con la muestra disponible.
Cuando H₀ es verdadera: el p-valor no tiene ningún pudor.
Supongamos que el alcalde de Villabajo tiene razón y los salarios son idénticos en ambos municipios. ¿Qué valores tomará el p-valor si repetimos el estudio 10.000 veces con distintas muestras? La respuesta teórica es elegante y, para muchos estudiantes, profundamente incómoda.
Bajo H₀ verdadera, el estadístico Z sigue una normal tipificada N(0,1). El p-valor es el área a la derecha de Z bajo esa misma curva. Como Z puede tomar cualquier valor con la probabilidad que le corresponde en la N(0,1), el p-valor resultante tiene exactamente la misma probabilidad de caer en cualquier subintervalo de [0,1] de igual longitud. Dicho de otro modo: el p-valor, cuando H₀ es verdadera, sigue una distribución uniforme en [0, 1]. La Figura 2 lo confirma con 10.000 simulaciones.
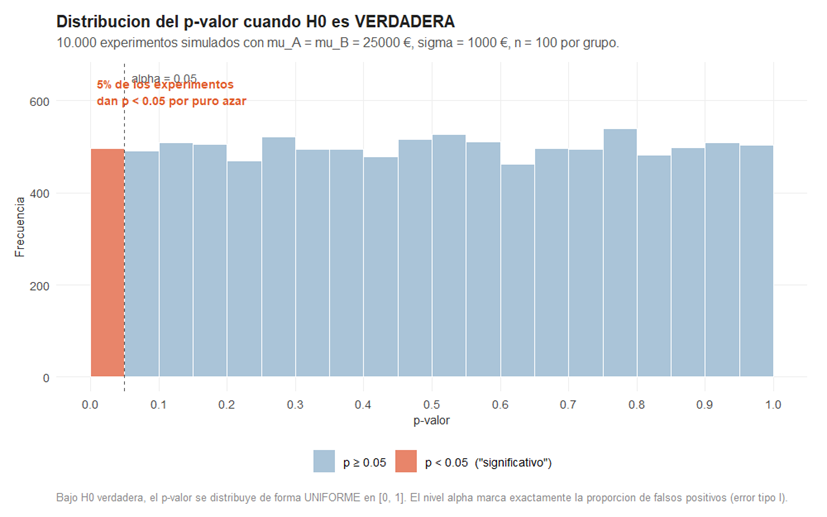
El histograma es prácticamente plano: todos los intervalos de p-valor tienen aproximadamente la misma altura. Y en particular, el 5% de los experimentos produce p < 0,05 aunque los salarios de Villarriba y Villabajo sean exactamente iguales. Esos son los falsos positivos o errores de tipo I: muestras que, por puro azar, arrojan una diferencia de medias suficientemente grande como para superar el valor crítico, llevando a rechazar H₀ sin que haya nada que rechazar.
Esto tiene una consecuencia directa que incomoda a mucha gente: si Villabajo encargara 20 estudios distintos sobre los salarios usando muestras independientes, y los salarios fueran realmente iguales, cabría esperar que en torno a uno de esos estudios concluyera que la diferencia es significativa, simplemente por azar. El umbral α = 0,05 no es una barrera mágica que separa lo real de lo ilusorio: es una tasa de error que decidimos tolerar. Si se hacen muchos contrastes sin corregir por esa multiplicidad, los falsos positivos se acumulan.
El problema del tamaño muestral: cuándo «significativo» no significa «importante».
Volvamos ahora al escenario en que los salarios de Villarriba sí son superiores a los de Villabajo, pero muy poco: exactamente 50 euros al mes de media, sobre un salario base de 25.000 euros anuales. Eso es el 0,2% de diferencia. Una cantidad que, con toda honestidad, no cambiaría la calidad de vida de nadie y que ningún economista consideraría relevante desde un punto de vista práctico.
En términos del estadístico tipificado, esa diferencia de 50 euros equivale a un δ muy pequeño: con σ = 1.000 euros y n = 100, el error estándar es de 141 euros, así que δ = 50/141 ≈ 0,35. Es una diferencia real que apenas desplaza la curva de H₁ respecto a la de H₀: las dos curvas casi se solapan, la potencia es baja y la mayoría de las muestras no detectarán nada. Sin embargo, lo que muestra la Figura 3 es que ese diagnóstico cambia radicalmente según el tamaño muestral.
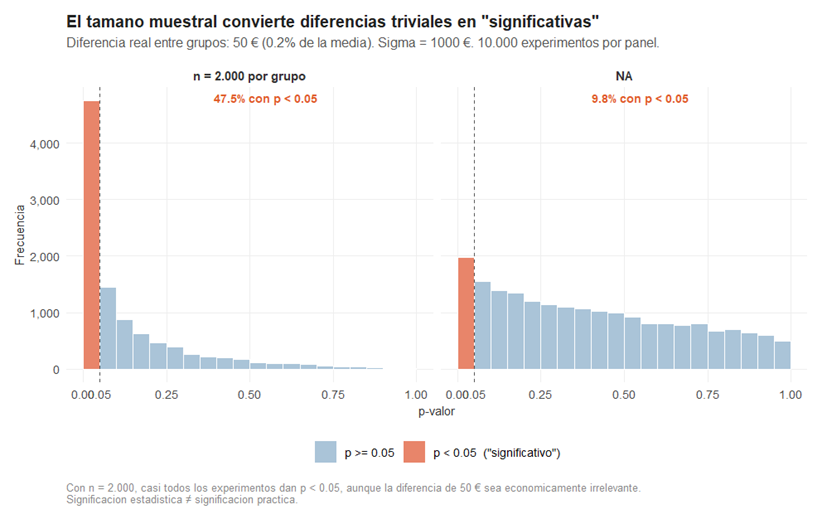
Con n = 2.000 trabajadores por grupo, casi la mitad de los experimentos —el 47,5%— concluyen que la diferencia es estadísticamente significativa. El contraste detecta con frecuencia una diferencia de 50 euros que no tiene ningún impacto real. Con muestras más pequeñas, el porcentaje de significativos cae, no porque la diferencia haya desaparecido, sino porque el error estándar es mayor y δ efectivo es menor: con n = 30, el error estándar sube a 258 euros y δ cae a 0,19, lo que hace que la diferencia de 50 euros sea prácticamente indetectable.
Esto revela una tensión fundamental del contraste clásico: con muestras muy grandes, todo acaba siendo estadísticamente significativo; con muestras pequeñas, nada lo es aunque deba serlo. El p-valor no mide la magnitud del efecto, sino su detectabilidad dadas las condiciones del estudio. Una diferencia de 50 euros y una de 500 euros pueden producir el mismo p-valor si el tamaño muestral se ajusta en consecuencia. Por eso, cuando Villabajo obtenga el informe y lea «significativo con p = 0,03», la primera pregunta que debe hacerse no es si puede rechazar H₀, sino cuánto es realmente la diferencia.
La curva de potencia: diseñar el estudio antes de recoger los datos.
Hay una pregunta que Villabajo debería haberse hecho antes de encargar el estudio: ¿cuántos trabajadores necesito encuestar para que el contraste tenga suficiente capacidad de detectar la diferencia si existe? Esa capacidad es la potencia del contraste, y la Figura 4 muestra cómo depende del tamaño muestral y de la diferencia real.
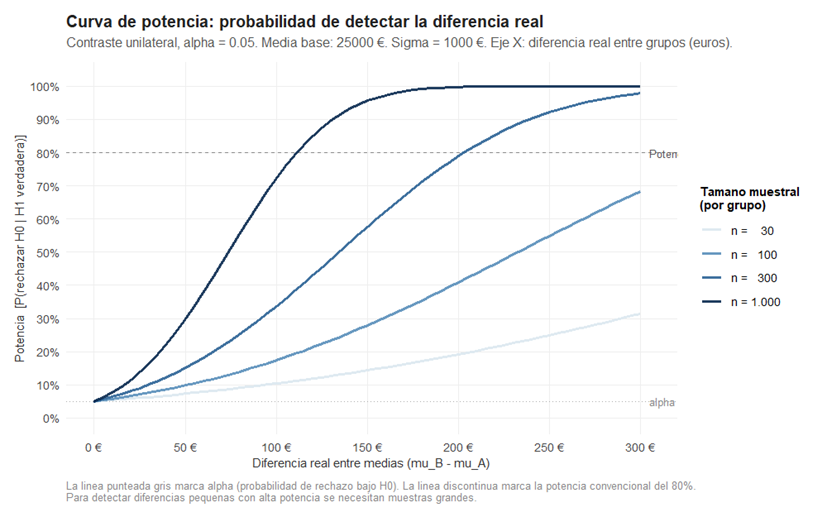
El eje horizontal muestra la diferencia real entre medias en euros —no el δ tipificado, sino la magnitud en la escala original—, y el eje vertical muestra la potencia correspondiente. Cada curva arranca en α = 5% cuando la diferencia real es cero —porque incluso sin efecto real, el 5% de las muestras llevaría a rechazar H₀— y sube hacia el 100% a medida que la diferencia crece.
La pendiente de esa subida depende críticamente de n. Con n = 1.000 por grupo, la curva asciende rápidamente y supera el 80% de potencia con diferencias de algo más de 100 euros: el contraste es sensible. Con n = 30, la curva es tan plana que incluso una diferencia de 300 euros se detecta menos del 30% de las veces: el contraste es prácticamente ciego.
La línea discontinua a la altura del 80% es la potencia mínima que se considera aceptable en la mayoría de disciplinas. Diseñar un estudio con potencia inferior al 80% equivale a buscar las llaves en la oscuridad con una linterna débil: se puede encontrar algo, pero la probabilidad de no encontrarlo aunque esté ahí es inaceptablemente alta. Villabajo, si quiere que su estudio sea interpretable, debería haberse preguntado de antemano cuál es la diferencia mínima que considera relevante y cuántas observaciones necesita para detectarla con un 80% de probabilidad. Ese cálculo, llamado análisis de potencia a priori, es tan parte del diseño de un estudio como la elección del nivel de significación. El tamaño de la muestra no es un detalle logístico que se decide al final según el presupuesto: es una decisión sobre cuánta evidencia se quiere recoger y qué efectos se quiere ser capaz de detectar. Estudios con potencia baja no solo fallan en detectar efectos reales; también generan resultados ambiguos que no permiten concluir nada claro, ni en un sentido ni en el otro.
Conclusión: lo que el p-valor no le dijo a Villabajo.
El informe llegó a Villabajo con un p-valor de 0,03. El alcalde, que había oído hablar del famoso umbral del 0,05, palideció: si el p-valor era menor que 0,05, «la diferencia era significativa» y Villarriba tenía razón. Encargó otro estudio. El nuevo informe devolvió un p-valor de 0,06. Respiración: «ahora no es significativo, estamos a salvo». Nadie le explicó que la diferencia entre 0,03 y 0,06 es estadísticamente trivial, que ambos estudios usaban tamaños muestrales distintos, ni que el p-valor no le decía nada sobre la magnitud real de la diferencia salarial.
El p-valor es una herramienta útil, pero con un alcance muy concreto: mide cuán sorprendentes serían los datos observados si H₀ fuera verdadera. No mide la probabilidad de que H₀ sea verdadera. No mide la importancia práctica del efecto. No garantiza que un resultado «significativo» sea real ni que uno «no significativo» sea nulo. Usarlo bien requiere entender qué distribución sigue el estadístico bajo H₀ y bajo H₁, qué papel juega el tamaño muestral, y qué significa exactamente el número que aparece en el informe.
La rivalidad entre Villarriba y Villabajo continúa. El último estudio, con n = 150 por grupo y un p-valor de 0,08, no encontró diferencias significativas.
El alcalde de Villabajo lo celebró con un banquete de empanadas.
El de Villarriba encargó un análisis de potencia.
El p-valor, impasible, espera.
Lecciones no siempre «tipificadas».
- La diferencia de medias muestrales es normal, y se tipifica. Bajo condiciones generales, la diferencia X̄A − X̄B sigue una distribución normal gracias al Teorema Central del Límite. Al dividir por el error estándar se obtiene Z ~ N(0,1) bajo H₀, lo que permite usar una única tabla de referencia independientemente de las unidades del problema.
- δ es el tamaño del efecto, no la diferencia en euros. El parámetro de no centralidad δ mide cuántas desviaciones típicas del estadístico separa la realidad de H₀. Hablar de δ = 1 o δ = 2 es más informativo que hablar de 141 o 282 euros, porque ya incorpora el tamaño muestral y la dispersión.
- El p-valor mide compatibilidad con H₀, no probabilidad de que H₀ sea verdadera. P(datos | H₀) y P(H₀ | datos) son cosas distintas. El p-valor es lo primero. Confundirlo con lo segundo es el error de interpretación más frecuente y más costoso.
- Bajo H₀ verdadera, el p-valor es uniforme. Todos los valores de [0,1] son igualmente probables cuando no hay efecto real. El 5% de los estudios darán p < 0,05 por azar. Multiplicar contrastes sin corregir infla artificialmente los falsos positivos.
- Significación estadística no implica relevancia práctica. Con n grande, diferencias minúsculas producen p-valores minúsculos. La pregunta sobre si una diferencia importa requiere evaluar su magnitud, no solo su p-valor.
- No rechazar H₀ no es confirmarla. Puede significar ausencia de efecto, o simplemente potencia insuficiente. Un estudio con potencia baja no puede distinguir entre «no hay diferencia» y «no tenemos datos suficientes para verla».
- El tamaño muestral debe calcularse antes, no después. El análisis de potencia a priori determina cuántas observaciones se necesitan para detectar el efecto mínimo relevante con una potencia aceptable. Es parte del diseño del estudio, no un detalle de última hora.
Deja una respuesta